额,你愿意写CPP调Dawn,还是愿意 await navigator.gpu.requestAdapter()?
我在快速验证想法的时候,更愿意选择自己更熟悉的 JavaScript API...
WGSL 还在积极讨论中,虽然各位大佬不是很满意这个新生儿。
不过,社区已经有了基础的实验性工具(VSCode 插件),并支持了较新的语法。
这个插件支持对文件扩展名为 .wgsl 的源代码文件进行高亮显示。
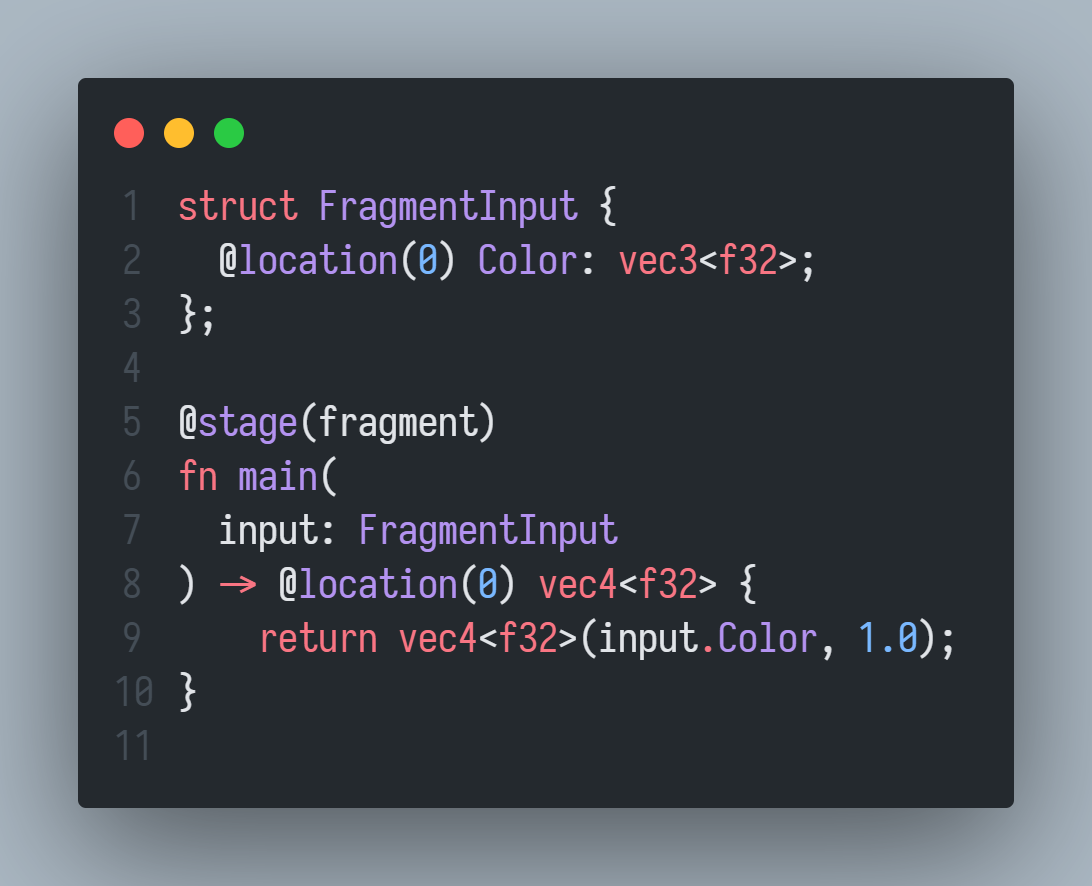
这个插件允许你在 JavaScript / TypeScript 的模板字符串中进行 wgsl 代码高亮,需要加上模板字符串前置块注释:
const code = /* wgsl */`
struct FragmentInput {
@location(0) Color: vec3<f32>;
};
@stage(fragment)
fn main(input: FragmentInput) -> @location(0) vec4<f32> {
return vec4<f32>(input.Color, 1.0);
}
`;

遗憾的是,截至 2022年3月25日,这两个插件并没有代码格式化功能(几乎没有),也没有代码智能提示功能。
这是一个 JavaScript / TypeScript 模板字符串 wgsl 预处理函数包,模板字符串除了可插值外,还可以使用前置函数进行预处理。
这个函数包目前只是一个 esm 模块文件,以后不排除会变成更大的 npm 包,由 toji(Brandon Jones)维护。
github.com/toji/wgsl-preprocessorgithub.com
这个使得 wgsl 拥有了 glsl 类似的宏定义等语法:
目前支持:
#if#elif#else#endif简单用法:
import { wgsl } from './wgsl-preprocessor.js';
function getDebugShader(sRGB = false) {
return wgsl`
@stage(fragment)
fn main() -> @location(0) vec4<f32> {
let color = vec4(1.0, 0.0, 0.0, 1.0);
#if ${sRGB}
let rgb = pow(color.rgb, vec3(1.0 / 2.2));
return vec4(rgb, color.a);
#else
return color;
#endif
}`;
}
`
因为模板字符串的插值功能已经可以当 #define 宏使用了,你甚至都不需要使用这个字符串预处理函数。
const ambientFactor = 1.0;
const sampleCount = 2;
const source = `
let ambientFactor = f32(${ambientFactor});
for (var i = 0u; i < ${sampleCount}u; i = i + 1u) {
// Etc...
}
`;
原文译名:WebGPU - 专注于处理核心(GPU Cores),而不是绘图画布(Canvas)
原文发布于 2022年3月8日,传送门 https://surma.dev/things/webgpu
这篇东西非常长,不计代码字符也有1w字,能比较好理解 WebGPU 的计算管线中的各个概念,并使用一个简单的 2D 物理模拟程序来理解它,本篇重点是在计算管线和计算着色器,绘图部分使用 Canvas2D 来完成。
WebGPU 是即将推出的 WebAPI,你可以用它访问图形处理器(GPU),它是一种底层接口。
原作者对图形编程没有多少经验,他是通过研究 OpenGL 构建游戏引擎的教程来学习 WebGL 的,还在 ShaderToy 上学习 Inigo Quilez 的例子来研究着色器。因此,他能在 PROXX 中创建背景动画之类的效果,但是他表示对 WebGL 并不太满意。别急,下文马上会解释。
当作者开始注意 WebGPU 后,大多数人告诉他 WebGPU 这东西比 WebGL 多很多条条框框。他没考虑这些,已经预见了最坏的情况,他尽可能找了一些教程和规范文档来看,虽然彼时并不是很多,因为他找的时候 WebGPU 还在早期制定阶段。不过,他深入之后发现 WebGPU 并没有比 WebGL 多所谓的“条条框框”,反而是像见到了一位老朋友一样熟悉。
所以,这篇文章就是来分享学到的东西的。
作者明确指出,他 不会 在这里介绍如何使用 WebGPU 绘制图形,而是要介绍 WebGPU 如何调用 GPU 进行它本身最原始的计算(译者注:也就是通用计算)。
他觉得已经有很多资料介绍如何用 WebGPU 进行绘图了,例如 austin 的例子,或许他考虑之后也写一些绘图方面的文章。
他在这里会讨论得比较深入,希望读者能正确、有效地使用 WebGPU,但是他不保证你读完就能成为 GPU 性能专家。
絮絮叨叨结束后,准备发车。
WebGL 是 2011 年发布的,迄今为止,它是唯一能在 Web 访问 GPU 的底层 API,实际上它是 OpenGL ES 2.0 的简易封装版以便能在 Web 中使用。WebGL 和 OpenGL 都是科纳斯组标准化的,这个工作组是图形界的 W3C,可以这么理解。
OpenGL 本身是一个颇具历史的 API,按今天的标准看,它不算是一个很好的 API,它以内部全局状态对象为中心。这种设计可以最大限度减少特定调用的 GPU 的 IO 数据量。但是,这种设计有很多额外的开销成本。
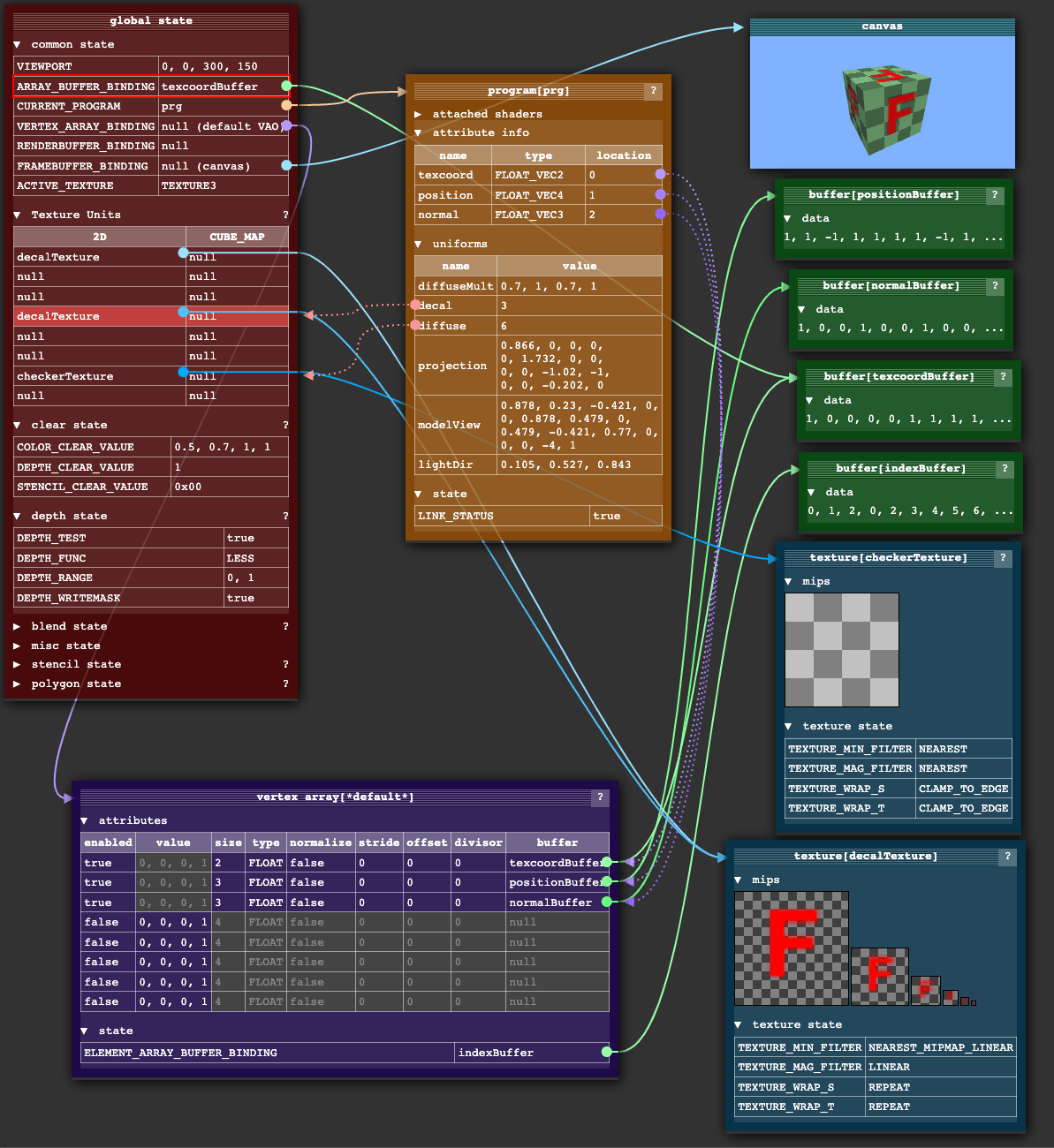
上图:WebGL 内部全局状态对象的可视化,源自 WebGL Fundamentals
内部状态对象,说白了,大多数都是一些指针。调用 OpenGL API 会改变这些指针的指向,所以改变状态的顺序相当重要,这导致了抽象和写库的困难程度大大增加。你必须非常清楚地知道你现在马上要进行的 API 调用需要准备什么状态,调用完了还得恢复到之前的值。
他说,他经常会看到一个黑色的画布(因为 WebGL 报错大多数时候就这样),然后得狂躁地找没调用哪些 API 没有正确设置全局状态。
他承认,他不知道 ThreeJS 是如何做到状态管理架构的,但是的确做的不错,所以大多数人会使用 ThreeJS 而不是原生 WebGL,这是主要的原因了。
“不能很好认同 WebGL”这只是对原作者他自己说的,而不是读者们。他表示,比他聪明的人用 WebGL 和 OpenGL 已经做了不少 nice 的东西,但是他一直不满意罢了。
随着机器学习、神经网络以及加密货币的出现,GPU 证明了它可以干除了画三角形之外的事情。使用 GPU 进行任意数据的计算,这种被称为 GPGPU,但是 WebGL 1.0 的目的并不在于此。如果你在 WebGL 1.0 想做这件事,你得把数据编码成纹理,然后在着色器中对数据纹理进行解码、计算,然后重新编码成纹理。WebGL 2.0 通过 转移反馈 让这摊子事情更容易了一些,但是直到 2021 年 9 月,Safari 浏览器才支持 WebGL 2.0(大多数浏览器 2017 年 1 月就支持了),所以 WebGL 2.0 不算是好的选择。
尽管如此,WebGL 2.0 仍然没有改变 WebGL 的本质,就是全局状态。
在 Web 领域外,新的图形 API 已经逐渐成型。它们向外部暴露了一套访问显卡的更底层的接口。这些新的 API 改良了 OpenGL 的局促性。
主要就是指 DirectX 12、Vulkan、Metal
一方面来说,现在 GPU 哪里都有,甚至移动设备都有不错的 GPU 了。所以,现代图形编程(3D渲染、光追)和 GPGPU 会越来越普遍。
另一方面来看,大多数设备都有多核处理器,如何优化多线程与 GPU 进行交互,是一个重要的课题。
WebGPU 标准制定者注意到了这些现状,在预加载 GPU 之前要做好验证工作,这样才能给 WebGPU 开发者以更多精力专注于压榨 GPU 的性能。
下一代最受欢迎的 GPU API 是:
为了把这些技术融合并带到 Web,WebGPU 就诞生了。
WebGL 是 OpenGL 的一个浅层封装,但是 WebGPU 并没这么做。它引入了自己的抽象概念体系,汲取上述 GPU API 的优点,而不是继承自这些更底层的 API.
原因很简单,这三个 API 并不是全部都是全平台通用的,而且有一些他们自己的非常底层的概念,对于 Web 这个领域来说显得不那么合理。
相反,WebGPU 的设计让人感觉“哇,这就是给 Web 设计的”,但是它的的确确又基于你当前机器的 GPU API,抽象出来的概念被 W3C 标准化,所有的浏览器都得实现。由于 WebGPU 相对来说比较底层,它的学习曲线会比较陡峭,但是作者表示会尽可能地分解。
最开始接触到的 WebGPU 抽象概念是适配器(Adapter)和设备(Device)。

上图:抽象层,从物理 GPU 到逻辑设备。
物理设备就是 GPU 本身,有内置的 GPU(核芯显卡)和外部 GPU(独立显卡)两种。通常,某个设备一般只有一个 GPU,但是也有两个或者多个的情况。例如,微软的 Surface 笔记本就具备双显卡,以便操作系统在不同的情况进行切换。
操作系统使用显卡厂商提供的驱动程序来访问 GPU;反过来,操作系统也可以用特定的 API(例如 Vulkan 或者 Metal)向外暴露 GPU 的功能。
GPU 是共享资源,它不仅要被各种程序调用,还要负责向显示器上输出。这看起来需要一个东西来让多个进程同时使用 GPU,以便每个进程把自己的东西画在屏幕上。
对于每个进程来说,似乎看起里他们对 GPU 有唯一的控制权,但是那只是表象,实际上这些复杂逻辑是驱动程序和操作系统来完成调度的。
适配器(Adapter) 是特定操作系统的 API 与 WebGPU 之间的中介。
但是,由于浏览器又是一个可以运行多个 Web 程序的“迷你操作系统”,因此,在浏览器层面仍需要共享适配器,以便每个 Web 程序感觉上就像唯一控制 GPU 一样,所以,每个 Web 程序就获得了再次抽象的概念:逻辑设备(Logical Device)。
要访问适配器对象,请调用 navigator.gpu.requestAdapter(),在写本文时,这个方法的参数比较少,能让你选请求的是高性能的适配器(通常是高性能独显)还是低功耗适配器(通常是核显)。
译者注:本篇讨论 WebGPU 的代码,没特殊指明,均为浏览器端的 WebGPU JavaScript API.
软渲染:一些操作系统(诸如小众 Linux)可能没有 GPU 或者 GPU 的能力不足,会提供“后备适配器(Fallback Adapter)”,实际上这种适配器是纯软件模拟出来的,它可能不是很快,可能是 CPU 模拟出来的,但是能基本满足系统运作。
若能请求到非空的适配器对象,那么你可以继续异步调用 adapter.requestDevice() 来请求逻辑设备对象。下面是示例代码:
if (!navigator.gpu) throw Error("WebGPU not supported.");
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) throw Error("Couldn’t request WebGPU adapter.");
const device = await adapter.requestDevice();
if (!device) throw Error("Couldn’t request WebGPU logical device.");
如果没有任何请求设备的参数,那么 requestDevice() 会返回一个不匹配任何设备功能要求的设备,即 WebGPU 团队认为是合理且对于所有 GPU 都通用的设备对象。
请求设备对象过程中的“限制”见 规范。
举个例子,即使我的 GPU 可以轻易处理 4GB 的数据,返回的设备对象也只允许最大 1GB 的数据,你请求再多也只会返回最大允许 1GB,这样就算你切换到别的机器上跑代码,就不会有太多问题。
你可以访问 adapter.limits 查看物理 GPU 的实际限制情况。也可以在请求设备对象时,传递你所需要检验的更高限制参数。
如果你用过 WebGL,那么你应该熟悉顶点着色器和片元(片段)着色器。其实也没多复杂,常规技术路线就是上载三角形缓冲数据到 GPU,告诉 GPU 缓冲数据是如何构成三角形的。顶点缓冲的每个顶点数据描述了顶点的位置,当然还包括颜色、纹理坐标、法线等其它辅助内容。每个顶点都要经过顶点着色器处理,以完成平移、旋转、透视变形等操作。
让原作者感到困惑的是“着色器”这个词,因为它除了着色之外还有别的作用。但是在很久以前(1980年代后期)来看,这个词非常合适,它在 GPU 上的功能就是计算出像素的颜色值。而如今,它泛指在 GPU 上运行的任何程序。
GPU 会对三角形进行光栅化处理,计算出每个三角形在屏幕上占据的像素。每个像素,则交由片段着色器处理,它能获取像素坐标,当然也可以加入一些辅助数据来决定该像素的最终着色。如果使用得当,就能绘制出令人惊叹的 3D 效果。
将缓冲数据传递到顶点着色器,然后继续传送到片段着色器,最终输出到屏幕上这一过程,可以简单的称之为管道(或管线,Pipeline),在 WebGPU 中,必须明确定义 Pipeline.
目前,WebGPU 支持两大管线:
顾名思义,渲染管线绘制某些东西,它结果是 2D 图像,这个图像不一定要绘制到屏幕上,可以直接渲染到内存中(被称作帧缓冲)。计算管线则更加通用,它返回的是一个缓冲数据对象,意味着可以输出任意数据。
在本文的其它部分会专注于计算管线的介绍,因为作者认为渲染管线算是计算管线的一种特殊情况。
现在开始算开历史倒车,计算管线原来其实是为了创建渲染管线而先做出来的“基础”,这些所谓的管线在 GPU 中其实就是不同的物理电路罢了。
基于上述理解,倘若未来向 WebGPU 中添加更多类型的管线,例如“光追管线”,就显得理所当然了。
使用 WebGPU API,管线由一个或多个可编程阶段组成,每个阶段由一个着色器模块和一个入口函数定义。计算管线拥有一个计算着色阶段,渲染管线有一个顶点着色阶段和一个片段着色阶段,如下所示是一个计算着色模块与计算管线:
const module = device.createShaderModule({
code: `
@stage(compute) @workgroup_size(64)
fn main() {
// ...
}
`,
})
const pipeline = device.createComputePipeline({
compute: {
module,
entryPoint: "main",
},
})
这是 WebGPU 的着色语言(WGSL,发音 /wig-sal/)的首次登场。
WGSL 给作者的初印象是 Rust + GLSL,它有很多类似 Rust 的语法,也有类似 GLSL 一样的全局函数(如 dot()、norm()、len() 等),以及类型(vec2、mat4x4 等),还有 swizzling 语法(例如 some_vec.xxy)。
浏览器会把 WGSL 源码编译成底层系统的着色器目标程序,可能是 D3D12 的 HLSL,也可能是 Metal 的 MSL,或者 Vulkan 的 SPIR-V.
SPIR-V:是科纳斯组标准化出来的开源、二进制中间格式。你可以把它看作并行编程语言中的
LLVM,它支持多种语言编译成它自己,也支持把自己翻译到其它语言。
在上面的着色器代码中,只创建了一个 main 函数,并使用 @stage(compute) 这个特性(Attribute,WGSL 术语)将其标记为计算着色阶段的入口函数。
你可以在着色器代码中标记多个 @stage(compute),这样就可以在多个管线中复用一个着色器模块对象了,只需传递不同的 entryPoint 选择不同的入口函数即可。
但是,@workgroup_size(64) 特性是什么?
GPU 以延迟为代价优化了数据吞吐量。想深入这点必须看一下 GPU 的架构,但是作者没信心讲好这块,所以建议看一看 Fabian Giesen 的 文章。
众所周知,GPU 有非常多个核心构成,可以进行大规模的并行运算。但是,这些核心不像 CPU 并行编程一样相对独立运作。首先,GPU 处理核心是分层分组的,不同厂商的 GPU 的设计架构、API 不尽一致。Intel 这里给了一个不错的文档,对他们的架构进行了高级的描述。
在 Intel 的技术中,最小单元被称作“执行单元(Execution Unit,EU)”,每个 EU 拥有 7 个 SIMT 内核 —— 意思是,它有 7 个以“锁步”(Lock-step)的方式运行同一个指令的并行计算核。每个内核都有自己的寄存器和调度缓存的指针,尽管执行着相同的操作,但是数据可以是不同的。
所以有时候不推荐在 GPU 上执行 if/else 判断分支,是因为 EU 的原因。因为 EU 遇到分支逻辑的时候,每个内核都要进行 if/else 判断,这就失去了并行计算的优势了。
对于循环也是如此。如果某个核心提前完成了计算任务,那它不得不假装还在运行,等待 EU 内其它核心完成计算。
尽管内核的计算频率很高,但是从内存中加载数据或者从纹理中采样像素的时间明显要更长 —— Fabian 同志说,这起码要耗费几百个时钟周期。这些时间显然可以拿来算东西。为了充分利用这些时钟周期,每个 EU 必须负重前行。
EU 空闲的时候,譬如在等内存的食物过来的时候,它可不会就一直闲下去,它会立马投入到下一个计算中,只有这下一个计算再次进入等待时,才会切换回来,切换的过程非常非常短。
GPU 就是以这样的技术为代价换来吞吐量的优化的。GPU 通过调度这些任务的切换机制,让 EU 一直处于忙碌状态。
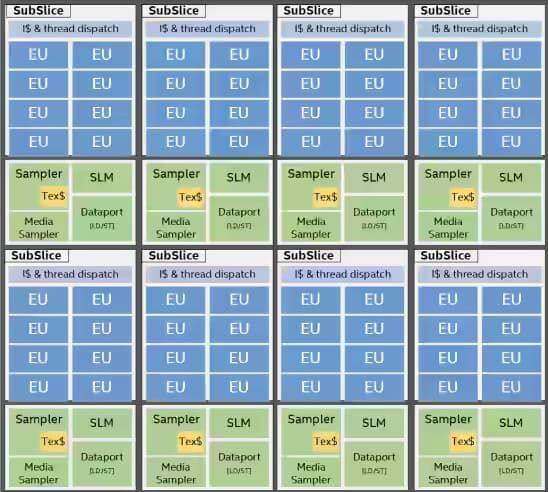
上图:Intel 锐炬 Xe 显卡芯片架构。它被分成 8 个子块,每个子块有 8 个 EU;每个 EU 拥有 7 个 SIMT 内核。
不过,根据上图来看,EU 只是 Intel 显卡设计架构层级最低的一个,多个 EU 被 Intel 分为所谓的“子块(SubSlice)”,子块中所有的 EU 都可以访问共有的局部缓存(Shared Local Memory,SLM),大概是 64KB,如果所运行的程序有同步指令,那么就必须在同一个子块中运行,因为这样才能共享内存。
再往上,子块就构成了块(Slice),构成 GPU;对于集成在 CPU 中的 GPU,大约有 170 ~ 700 个内核。对于独立显卡,则会有 1500 或以上个内核。
其它厂商也许会用其它的术语,但是架构基本上可以这么类比理解。
为了充分利用 GPU 的架构优势,需要专门写程序调用,这样就可以最大限度地压榨 GPU 的性能。所以,图形 API 得向外暴露类似的线程模型来调用计算任务。
在 WebGPU API 中,这种线程模型就叫做“工作组(Workgroup)”。
每个顶点都会被顶点着色器处理一次,每个片元则会被片元着色器处理一次(当然,这是简单说法,忽略了很多细节)。
而在 GPGPU 中,与顶点、片元类似的概念是需要开发者自己定义的,这个概念叫做 计算项,计算项会被计算着色器处理。
一组计算项就构成了“工作组”,作者称之为“工作负载”。工作组中的每个计算项会被同时运行的计算着色器作用。在 WebGPU 中,工作组可以想象成一个三维网格,最小层级的是计算项,计算项构成稍大级别的是工作组,再往上就构成规模更大的工作负载。

上图:这是一个工作负载,其中红色小立方体由 4³ 个白色小立方体构成,白色小立方是计算项,而红色小立方体则由这 64 个白色小立方构成,即工作组。
基于上述概念,就可以讨论 WGSL 中的 @workgroup_size(x, y, z) 特性了,它的作用很简单,就是告诉 GPU 这个计算着色器作用的工作组有多大。用上面的图来说,其实就是红色小立方的大小。x*y*z 是每个工作组的计算项个数,如果不设某个维度的值,那默认是 1,因此,@workgroup_size(64) 等同于 @workgroup_size(64, 1, 1).
当然,实际 EU 的架构当然不会是这个 3D 网格里面的某个单元。使用这个图来描述计算项的目的是凸显出一种局部性质,即假设相邻的工作组大概率会访问缓存中相似的区域,所以顺次运行相邻的工作组(红色小立方)时,命中缓存中已有的数据的几率会更高一些,而无需在再跑去显存要数据,节省了非常多时间周期。
然而,大多数硬件依旧是顺序执行工作组的,所以设置 @workgroup_size(64) 和 @workgroup_size(8, 8) 的两个不同的着色器实际上差异并不是很大。所以,这个设计上略显冗余。
工作组并不是无限维度的,它受设备对象的限制条件约束,打印 device.limits 可以获取相关的信息:
console.log(device.limits)
/*
{
// ...
maxComputeInvocationsPerWorkgroup: 256,
maxComputeWorkgroupSizeX: 256,
maxComputeWorkgroupSizeY: 256,
maxComputeWorkgroupSizeZ: 64,
maxComputeWorkgroupsPerDimension: 65535,
// ...
}
*/
可以看到,每个维度上都有最大限制,而且累乘的积也有最大限制。
提示:避免申请每个维度最大限制数量的线程。虽然 GPU 由操作系统底层调度,但如果你的 WebGPU 程序霸占了 GPU 太久的话,系统有可能会卡死。
那么,合适的工作组大小建议是多少呢?这需要具体问题具体分析,取决于工作组各个维度有什么指代含义。作者认为这答案很含糊,所以他引用了 Corentin 的话:“用 64 作为工作组的大小(各个维度累乘后),除非你十分清楚你需要调用 GPU 干什么事情。”
64 像是个比较稳妥的线程数,在大多数 GPU 上跑得还可以,而且能让 EU 尽可能跑满。
到目前为止,已经写好了着色器并设置好了管线,剩下的就是要调用 GPU 来执行。由于 GPU 可以是有自己内存的独立显卡,所以可以通过所谓的“指令缓冲”或者“指令队列”来控制它。
指令队列,是一块内存(显示内存),编码了 GPU 待执行的指令。编码与 GPU 本身紧密相关,由显卡驱动负责创建。WebGPU 暴露了一个“CommandEncoder”API 来对接这个术语。
const commandEncoder = device.createCommandEncoder()
const passEncoder = commandEncoder.beginComputePass()
passEncoder.setPipeline(pipeline)
passEncoder.dispatch(1)
passEncoder.end()
const commands = commandEncoder.finish()
device.queue.submit([commands])
commandEncoder 对象有很多方法,可以让你把某一块显存复制到另一块,或者操作纹理对应的显存。它还可以创建 PassEncoder(通道编码器),它可以配置管线并调度编码指令。
在上述例子中,展示的是计算管线,所以创建的是计算通道编码器。调用 setPipeline() 设置管线,然后调用 dispatch() 方法告诉 GPU 在每个维度要创建多少个工作组,以备进行计算。
换句话说,计算着色器的调用次数等于每个维度的大小与该维度调用次数的累积。
例如,一个工作组的三个维度大小是 2, 4, 1,在三个维度上要运行 4, 2, 2 次,那么计算着色器一共要运行 2×4 + 4×2 + 1×2 = 18 次。
顺便说一下,通道编码器是 WebGPU 的抽象概念,它就是文章最开始时作者抱怨 WebGL 全局状态机的良好替代品。运行 GPU 管线所需的所有数据、状态都要经过通道编码器来传递。
抽象:指令缓冲也只不过是显卡驱动或者操作系统的钩子,它能让程序调用 GPU 时不会相互干扰,确保相互独立。指令推入指令队列的过程,其实就是把程序的状态保存下来以便待会要用的时候再取出,因为硬件执行的速度非常快,看起来就是各做各的,没有受到其它程序的干扰。
跑起代码,因为 workgroup_size 特性显式指定了 64 个工作组,且在这个维度上调用了 1 次,所以最终生成了 64 个线程,虽然这个管线啥事儿都没做(因为没写代码),但是至少起作用了,是不是很酷炫?
随后,我们搞点数据来让它起作用。
如文章开头所言,作者没打算直接用 WebGPU 做图形绘制,而是打算拿它来做物理模拟,并用 Canvas2D 来简单的可视化。虽然叫是叫物理模拟,实际上就是生成一堆圆几何,让它们在平面范围内随机运动并模拟他们之间相互碰撞的过程。
为此,要把一些模拟参数和初始状态传递到 GPU 中,然后跑计算管线,最后读取结果。
这可以说是 WebGPU 最头皮发麻的的一部分,因为有一堆的数据术语和操作要学。不过作者认为恰好是这些数据概念和数据的行为模式造就了 WebGPU,使它成为了高性能的且与设备无关的 API.
为了与 GPU 进行数据交换,需要一个叫绑定组的布局对象(类型是 GPUBindGroupLayout)来扩充管线的定义。
首先要说说绑定组(类型是 GPUBindGroup),它是某种管线在 GPU 执行时各个资源的几何,资源即 Buffer、Texture、Sampler 三种。
而先于绑定组定义的绑定组布局对象,则记录了这些资源的数据类型、用途等元数据,使得 GPU 可以提前知道“噢,这么回事,提前告诉我我可以跑得更快”。
下列创建一个绑定组布局,简单起见,只设置一个存储型(type: "storage")的缓冲资源:
const bindGroupLayout = device.createBindGroupLayout({
entries: [{
binding: 1,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "storage",
}
}]
})
// 紧接着,传递给管线
const pipeline = device.createComputePipeline({
layout: device.createPipelineLayout({
bindGroupLayouts: [bindGroupLayout]
}),
compute: {
module,
entryPoint: 'main'
}
})
binding 这里设为了 1,可以自由设定(当然得按顺序),它的作用是在 WGSL 代码中与相同 binding 值的 buffer 变量绑定在一起。
@group(0) @binding(1)
var<storage, write> output: array<f32>;
type 字段是 "storage",即说明这个 Buffer 的类型是存储型。它还可以设置为其它的选项,其中 "read-only-storage" 即“只读存储型”,即着色器只能读,但是不能写这个 Buffer,只读型缓冲可以优化一些读写同步的问题;而 "uniform" 则说明 Buffer 类型是统一数据(Uniform),作用和存储型差不多(在着色器中值都一样)。
至此,绑定组布局对象创建完毕,然后就可以创建绑定组了,这里就不写出来了;一旦创建好了对应的绑定组和存储型 Buffer,那么 GPU 就可以开始读取数据了。
但是,在此之前,还有一个问题要讨论:暂存缓冲区。
这个小节的内容略长,请耐心阅读。
作者再次强调:GPU 以延迟为代价,高度优化了数据 IO 性能。GPU 需要相当快的速度向内核提供数据。在 Fabian 他 2011 年的博客中做了一些计算,得出的结论是 GPU 需要维持 3.3 GB/s 的速度才能运行 1280×720 分辨率的纹理的采样计算。
为了满足现在的图形需求,GPU 还要再快。只有 GPU 的内核与缓冲存储器高度集成才能实现,这意味着也就难以把这些存储区交由 CPU 来读写。
我们都知道 GPU 有自己的内存,叫显存,CPU 和 GPU 都可以访问它,它与 GPU 的集成度不高,一般在电路板的旁边,它的速度就没那么快了。
暂存缓冲区(Staging buffers),是介于显存和 GPU 之间的缓存,它可以映射到 CPU 端进行读写。为了读取 GPU 中的数据,要先把数据从 GPU 内的高速缓存先复制到暂存缓冲区,然后把暂存缓冲区映射到 CPU,这样才能读取回主内存。对于数据传递至 GPU 的过程则类似。
回到代码中,创建一个可写的 Buffer,并添加到绑定组,以便计算着色器可以写入它;同时还创建一个大小一样的 Buffer 以作为暂存。创建这些 Buffer 的时候,要用位掩码来告知其用途(usage),GPU 会根据参数申请、创建这些缓冲区,如果不符合 WebGPU 规则,则抛出错误:
const BUFFER_SIZE = 1000
const output = device.createBuffer({
size: BUFFER_SIZE,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC
})
const stagingBuffer = device.createBuffer({
size: BUFFER_SIZE,
usage: GPUBufferUsage.MAP_READ | GPUBufferUsage.COPY_DST
})
const bindGroup = device.createBindGroup({
layout: bindGroupLayout,
entries: [{
binding: 1,
resource: {
buffer: output
}
}]
})
注意,createBuffer() 返回的是 GPUBuffer 对象,不是 ArrayBuffer,创建完 Buffer 后还不能马上写入或者读取。为了实现读写 Buffer,需要有单独的 API 调用,而且 Buffer 必须有 GPUBufferUsage.MAP_READ 或 GPUBufferUsage.MAP_WRITE 的用途才能读或写。
TypeScript 提示:在各开发环境还未加入 WebGPU API 时,想要获得 TypeScript 类型提示,还需要安装 Chrome WebGPU 团队维护的
@webgpu/types包到你的项目中。
到目前为止,不仅有绑定组的布局对象,还有绑定组本身,现在需要修改通道编码器部分的代码以使用这个绑定组,随后还要把 Buffer 中计算好的数据再读取回 JavaScript:
const commandEncoder = device.createCommandEncoder();
const passEncoder = commandEncoder.beginComputePass();
passEncoder.setPipeline(pipeline)
passEncoder.setBindGroup(0, bindGroup)
passEncoder.dispatch(1)
passEncoder.dispatch(Math.ceil(BUFFER_SIZE / 64))
passEncoder.end()
commandEncoder.copyBufferToBuffer(
output,
0, // 从哪里开始读取
stagingBuffer,
0, // 从哪里开始写
BUFFER_SIZE
)
const commands = commandEncoder.finish()
device.queue.submit([commands])
await stagingBuffer.mapAsync(
GPUMapMode.READ,
0, // 从哪里开始读,偏移量
BUFFER_SIZE // 读多长
)
const copyArrayBuffer = stagingBuffer.getMappedRange(0, BUFFER_SIZE)
const data = copyArrayBuffer.slice()
stagingBuffer.unmap()
console.log(new Float32Array(data))
稍前的代码中,管线对象借助管线布局添加了绑定组的局对象,所以如果在通道编码的时候不设置绑定组就会引起调用(dispatch)失败。
在计算通道 end() 后,指令编码器紧接着触发一个缓冲拷贝方法调用,将数据从 output 缓冲复制到 stagingBuffer 缓冲,最后才提交指令编码的指令缓冲到队列上。
GPU 会沿着队列来执行,没法推测什么时候会完成计算。但是,可以异步地提交 stagingBuffer 缓冲的映射请求;当 mapAsync 被 resolve 时,stagingBuffer 映射成功,但是 JavaScript 仍未读取,此时再调用 stagingBuffer.getMappedRange() 方法,就能获取对应所需的数据块了,返回一个 ArrayBuffer 给 JavaScript,这个返回的缓冲数组对象就是显存的映射,这意味着如果 stagingBuffer 的状态是未映射时,返回的 ArrayBuffer 也随之没有了,所以用 slice() 方法来拷贝一份。
显然,可以在控制台看到输出效果:
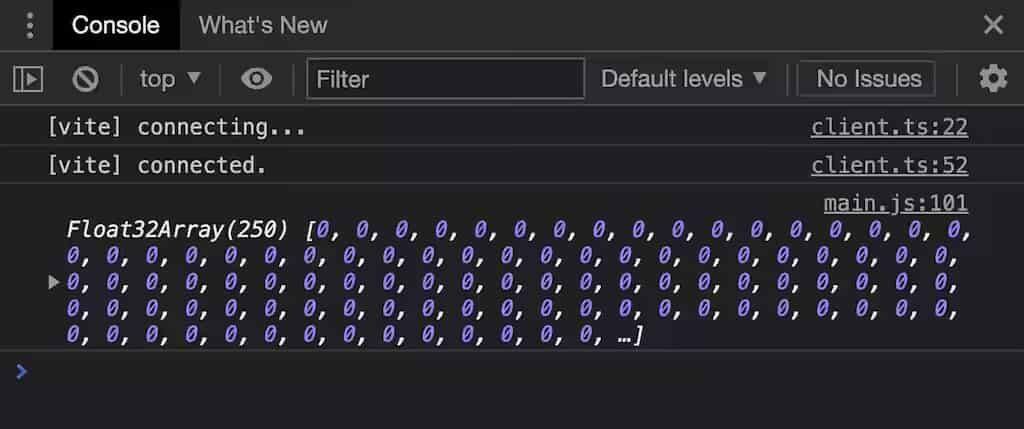
上图:凑合,但是说明了一个问题,那就是从 GPU 显存中把这堆 0 给拿下来了
或许,制造点 0 之外的数据会更有说服力。在进行高级计算之前,先搞点人工数据到 Buffer 中,以证明计算管线确实按预期在运行:
@group(0) @binding(1)
var<storage, write> output: array<f32>;
@stage(compute) @workgroup_size(64)
fn main(
@builtin(global_invocation_id)
global_id : vec3<u32>,
@builtin(local_invocation_id)
local_id : vec3<u32>,
) {
output[global_id.x] =
f32(global_id.x) * 1000. + f32(local_id.x);
}
前两行声明了一个名为 output 的模块范围的变量,它是一个 f32 元素类型的数组。它的两个特性声明了来源,@group(0) 表示从第一个(索引为 0)绑定组中获取第 1 个绑定资源。output 数组是动态长度的,会自动反射对应 Buffer 的长度。
WGSL 变量:与 Rust 不同,let 声明的变量是不可变的,如果希望变量可变,使用 var 声明
接下来看 main 函数。它的函数签名有两个参数 global_id 和 local_id,当然这两个变量的名称随你设定,它们的值取决于对应的内置变量 global_invocation_id、local_invocation_id,分别指的是 工作负载 中此着色器调用时的全局 x/y/z 坐标,以及 工作组 中此着色器调用时的局部 x/y/z 坐标。
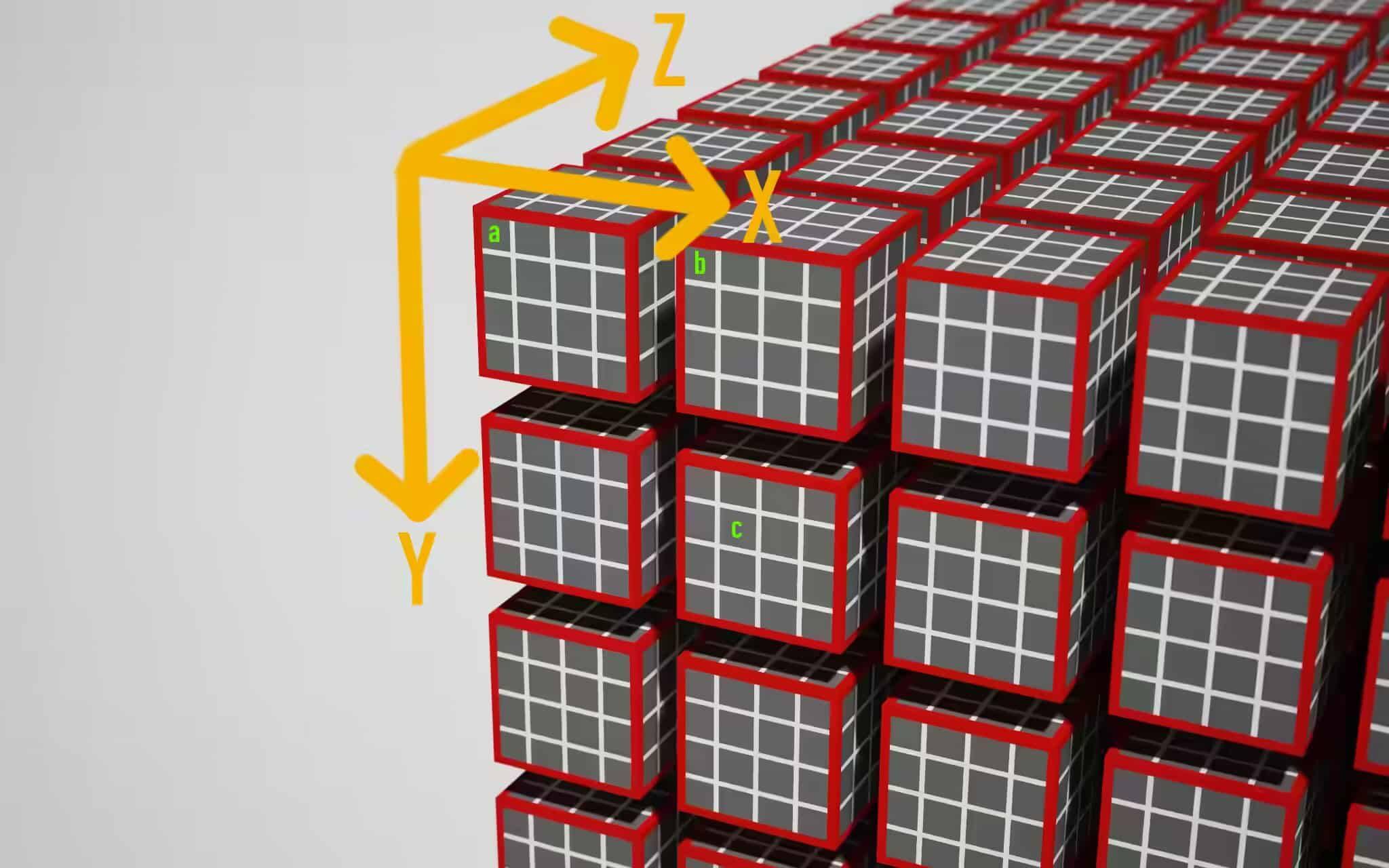
上图:三个计算项,a、b、c,用绿色字母标注。
这张图中使用的工作组大小是 @workgroup_size(4, 4, 4),使用图中的坐标轴顺序,那么对于图中的 a、b、c 计算项:
local_id = (x=0, y=0, z=0),global_id = (x=0, y=0, z=0)local_id = (x=0, y=0, z=0),global_id = (x=4, y=0, z=0)local_id = (x=1, y=1, z=0),global_id = (x=5, y=5, z=0)而对于我们的例子来说,工作组的大小被设为 @workgroup_size(64, 1, 1),所以 local_id.x 的取值范围是 0 ~ 63. 为了能检查 local_id 和 global_id,作者把这两个值进行编码,合成一个数字;注意,WGSL 类型是严格的,local_id 和 global_id 都是 vec3<u32>,因此要显式地转换为 f32 类型才能写入 output 缓冲区。
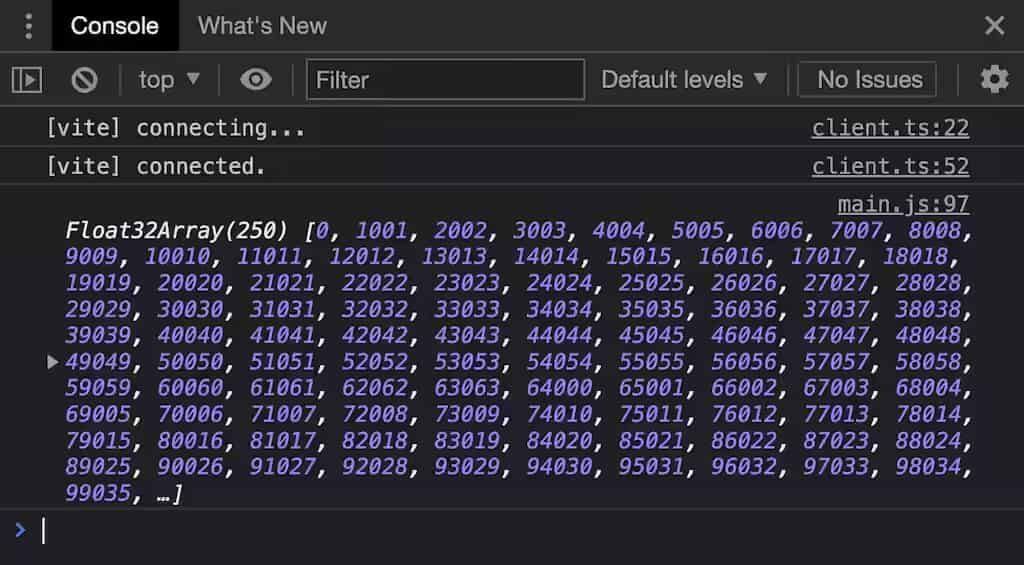
上图:GPU 写入的实际值,注意 local_id 是 63 为循环的终点,而 global_id 则仍旧在继续编码
上图证明了计算着色器确实向缓冲区输出了值,但是很容易发现这些数字看似是没什么顺序的,因为这是故意留给 GPU 去做的。
你可能会注意到,计算通道编码器的调度方法调度次数 Math.ceil(BUFFER_SIZE / 64) * 64 这个值,算出来就是 1024:
passEncoder.dispatch(Math.ceil(BUFFER_SIZE / 64))
这直接导致着色器代码中 global_id.x 的取值能取到 1024,大于 Buffer 的长度 1000.
不过还好,WGSL 是有保护超出数组索引范围的机制的,即一旦发生对数组索引越界的写入,那么总是会写入最后一个元素。这样虽然可以避免内存访问错误,但是仍有可能会生成一些无效数据。譬如,你把 JavaScript 端返回的 Float32Array 的最后 3 个元素打印出来,它们是 247055、248056、608032;如何避免因数组索引越界而可能发生的无效数据问题呢?可以用卫语句提前返回:
fn main( /* ... */ ) {
if (global_id.x >= arrayLength(&output)) {
return;
}
output[global_id.x] = f32(global_id.x) * 100. + f32(local_id.x)
}
若读者感兴趣,可以运行这个例子看效果。
还记得目标吗?是在 2D 的 Canvas 中移动一些圆,并让他们激情地碰撞。
所以,每个圆都要有一个半径参数和一个坐标参数,以及一个速度矢量。可以继续用 array<f32> 来表示上述数据,例如第一个数字是 x 坐标,第二个数字是 y 坐标,以此类推。
然而,这看起来有点蠢,WGSL 是允许自定义结构体的,把多条数据关联在一个结构内。
注意:如果你知道什么是内存对齐,你可以跳过本小节;如果你不知道,作者也没打算仔细解释,他打算直接展示为什么要这么做。
因此,定义一个结构体 Ball,表示 2D 中的圆,并使用 array<Ball> 表示一系列的 2D 圆球。
使用结构体,就不得不讨论内存对齐问题。
struct Ball {
radius: f32;
position: vec2<f32>;
velocity: vec2<f32>;
}
@group(0) @binding(1)
var<storage, write> output: array<Ball>;
@stage(compute) @workgroup_size(64)
fn main(
@builtin(global_invocation_id) global_id: vec3<u32>,
@builtin(local_invocation_id) local_id: vec3<u32>,
) {
let num_balls = arrayLength(&output);
if (global_id.x >= num_balls) {
return;
}
output[global_id.x].radius = 999.;
output[global_id.x].position = vec2<f32>(global_id.xy);
output[global_id.x].velocity = vec2<f32>(local_id.xy);
}
你可以运行这个代码,打开控制台可以看到:
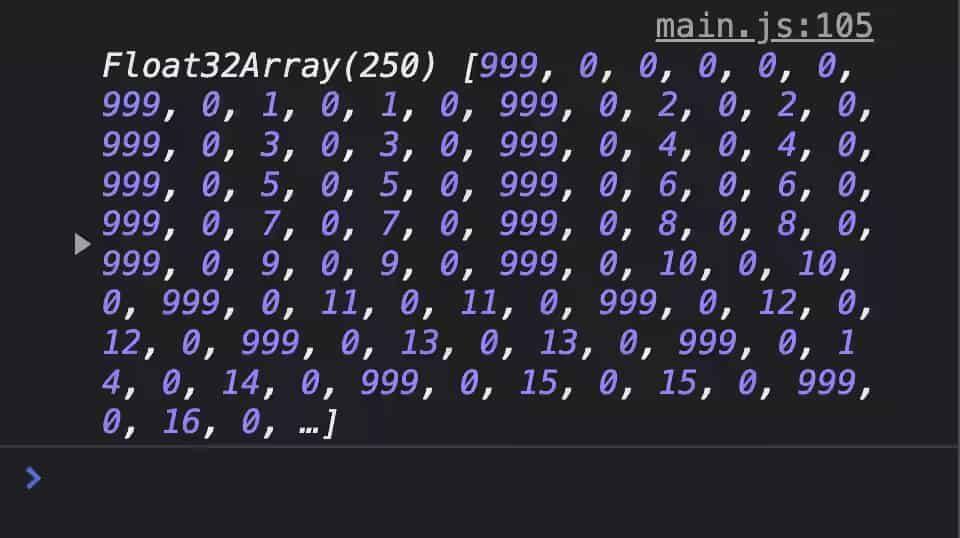
上图:因为内存对齐的原因,这个 TypedArray 有明显的数据填充现象
着色器代码首先把数据 999.0 写入到结构体的第一个字段 radius 中,以便于观察两个结构的分隔界限;但是,这个打印的 Float32Array 中,两个 999 数字之间,实际上跨越了 6 个数字,譬如上图中 0~5 位数字是 999, 0, 0, 0, 0, 0,紧随其后的 6~11 位数字是 999, 0, 1, 0, 1, 0,这就意味着每个结构体都占据了 6 个数字,但是 Ball 结构体明明只需要 5 个数字即可存储:radius、position.x、position.y、velocity.x 和 velocity.y. 很明显,每个 radius 后面都塞多了一个 0,这是为什么呢?
原因就是内存对齐。每一种 WGSL 中的数据类型都要严格执行对齐要求。
若一个数据数据类型的对齐尺度是 N(字节),则意味着这个类型的数据值只能存储在 N 的倍数的内存地址上。举个例子,f32 的对齐尺度是 4(即 N = 4),vec2<f32> 的对齐尺度是 8(即 N = 8).
假设 Ball 结构的内存地址是从 0 开始的,那么 radius 的存储地址可以是 0,因为 0 是 4 的倍数;紧接着,下个字段 position 是 vec2<f32> 类型的,对齐尺度是 8,问题就出现了 —— 它的前一个字段 radius 空闲地址是第 4 个字节,并非 position 对齐尺度 8 的倍数,为了对齐,编译器在 radius 后面添加了 4 个字节,也就是从第 8 个字节开始才记录 position 字段的值。这也就说明了控制台中看到 999 之后的数字为什么总是 0 的原因了。
现在,知道结构体在内存中是如何分布字节数据的了,可以在 JavaScript 中进行下一步操作了。
我们已经从 GPU 中读取到数据了,现在要在 JavaScript 中解码它,也就是生成所有 2D 圆的初始状态,然后再次提交给 GPU 运行计算着色器,让它“动起来”。初始化很简单:
let inputBalls = new Float32Array(new ArrayBuffer(BUFFER_SIZE))
for (let i = 0; i < NUM_BALLS; i++) {
inputBalls[i * 6 + 0] = randomBetween(2, 10) // 半径
inputBalls[i * 6 + 1] = 0 // 填充用
inputBalls[i * 6 + 2] = randomBetween(0, ctx.canvas.width) // x坐标
inputBalls[i * 6 + 3] = randomBetween(0, ctx.canvas.height) // y坐标
inputBalls[i * 6 + 4] = randomBetween(-100, 100) // x 方向速度分量
inputBalls[i * 6 + 5] = randomBetween(-100, 100) // y 方向速度分量
}
小技巧:如果你以后的程序用到了更复杂的数据结构,使用 JavaScript 拼凑这些字节码会非常麻烦,你可以用 Google 的 buffer-backed-object 库去创建复杂的二进制数据(类似序列化)。
还记得如何把 Buffer 传递给着色器吗?不记得的回去看看上文。只需要调整一下计算管线的绑定组布局即可接收新的 Buffer:
const bindGroupLayout = device.createBindGroupLayout({
entries: [
{
binding: 0,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: 'read-only-storage'
}
},
{
binding: 1,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: 'storage'
}
}
]
})
然后创建一个新的绑定组来传递初始化后的 2D 圆球数据:
const input = device.createBuffer({
size: BUFFER_SIZE,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_DST
})
const bindGroup = device.createBindGroup({
layout: bindGroupLayout,
entries: [
{
binding: 0,
resource: {
buffer: input // 输入初始化数据
}
},
{
binding: 1,
resource: {
buffer: output
}
}
]
})
就像读取数据一样,从技术角度来看,为了输入初始化的 2D 圆球数据,要创建一个可映射的暂存缓冲区 input,作为着色器读取数据的容器。
WebGPU 提供了一个简单的 API 便于我们把数据写进 input 缓冲区:
device.queue.writeBuffer(input, 0, inputBalls)
就是这么简单,并不需要指令编码器 —— 也就是说不需要借助指令缓冲,writeBuffer() 是作用在队列上的。
device.queue 对象还提供了一些方便操作纹理的 API.
现在,在着色器代码中要用新的变量来与这个新的 input 缓冲资源绑定:
// ... Ball 结构定义 ...
@group(0) @binding(0)
var<storage, read> input: array<Ball>;
// ... output Buffer 的定义
let TIME_STEP: f32 = 0.016;
@stage(compute) @workgroup_size(64)
fn main(
@builtin(global_invocation_id)
global_id: vec3<u32>
) {
let num_balls = arrayLength(&output);
if (global_id.x >= num_balls) {
return;
}
// 更新位置
output[global_id.x].position =
input[global_id.x].position +
input[global_id.x].velocity * TIME_STEP;
}
希望大部分着色器代码你能看得懂。
最后要做的,只是把 output 缓冲再次读取回 JavaScript,写一些 Canvas2D 的可视化代码把 Ball 的运动效果展示出来(需要用到 requestAnimationFrame),你可以看示例效果:demo
3.5 小节最后演示的代码只是能让 Ball 运动起来,还没有特别复杂的计算。在进行性能观测之前,要在着色器中加一些适当的物理计算。
作者就不打算解释物理计算了,写到这里,博客已经很长了,但是他简单的说明了物理效果的核心原理:每个 Ball 都与其它的 Ball 进行碰撞检测计算。
如果你十分想知道,可以看看最终的演示代码:final-demo,在 WGSL 代码中你还可以找到物理计算的资料连接。
作者并未优化物理碰撞算法,也没有优化 WebGPU 代码,即使是这样,在他的 MacBook Air(M1处理器)上表现得也很不错。
当超过 2500 个 Ball 时,帧数才掉到 60 帧以下,然而使用 Chrome 开发者工具去观测性能信息时,掉帧并不是 WebGPU 的问题,而是 Canvas2D 的绘制性能不足 —— 使用 WebGL 或 WebGPU 绘图就不会出现这个问题了。
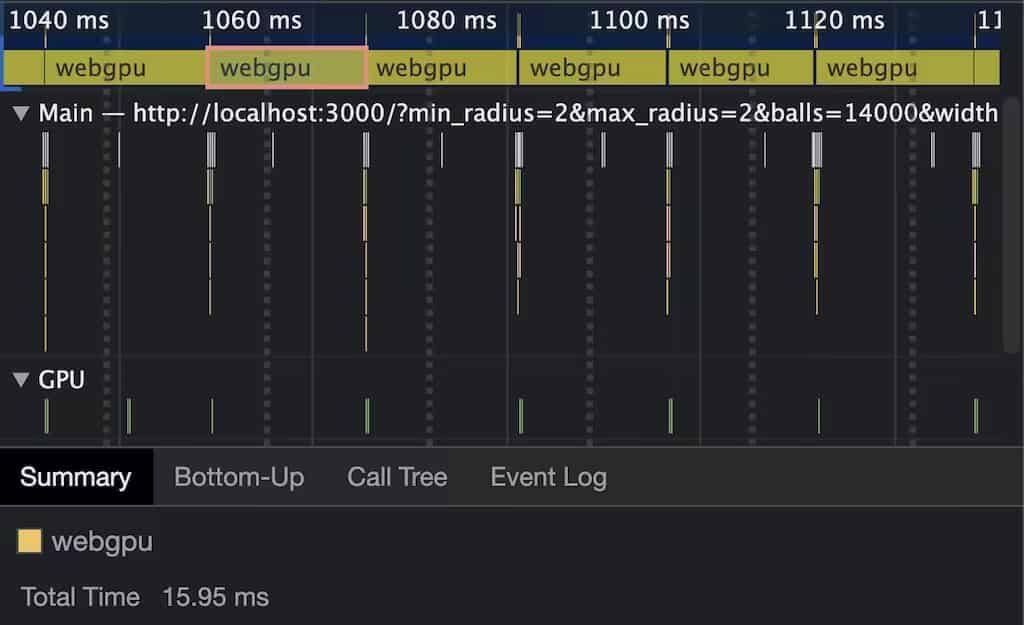
上图:即使是 14000 个 Ball,WebGPU 在 M1 处理器的 MBA 笔记本上也才用了 16 毫秒的单帧计算时间
作者关闭了 Canvas2D 绘图,加入 performance.measure() 方法来查看 16毫秒之内究竟可以模拟多少个 Ball 的物理计算。
这性能表现还是没有优化过的,已经让作者为之陶醉。
WebGPU 已经开发了蛮久了,作者认为制定规范的人希望 API 是稳定的。
话是这么说没错,但是 WebGPU API 目前只能跑在 Chrome 类浏览器和 FireFox 浏览器上,对 Safari 保持乐观态度 —— 虽然写本文时,Safari TP(技术预览)还没什么东西能看。
在稳定性表现上,即使是写文章的这段时间里,也是有变化的。
例如,WGSL 着色器代码的特性语法,从双方括号改为 @ 符号:
[[stage(compute), workgroup_size(64)]]
↓
@stage(compute) @workgroup_size(64)
对通道编码器结束的方法,Firefox 浏览器仍然是 endPass(),而 Chrome 类浏览器已经改为最新的 end().
规范中还有一些内容也并不是完全实现在所有浏览器上的,用于移动设备的 API 以及部分着色器常量就是如此。
基本上,WebGPU 进入 stable 阶段后,不排除会发生很多重大变化。
“在 Web 上能直接使用 GPU”这种现代的 API 看起来很好玩。在经历过最初的陡峭学习曲线后,作者认为真的可以使用 JavaScript 调用 GPU 进行大规模并行运算了。
wgpu 是使用 Rust 实现的 WebGPU,你可以在浏览器之外使用 Rust 语言调用 WebGPU 规范的 API;wgpu 还支持编译到 WebAssembly,你甚至可以使用 Rust 的 wgpu 编写 wasm,然后再放到浏览器运行高性能的代码。
还有个有趣的东西:Deno 借助 wgpu,内置了 WebGPU 的支持。
如果你有啥问题,你可以去 WebGPU Matrix 频道(国内可能访问不太通畅)提问,那里有一些 WebGPU 的用户、浏览器工程师和制定规范的人。
感谢 Brandon Jones 校对本文,感谢 WebGPU Matrix 频道解惑。
也感谢原作者分享这篇长文。
其实,写到第六篇比对基本上常规的 API 就差不多比对完了(除了 GPGPU、查询方面的 API 未涉及),但是有一个细节仍然值得我开一篇比对文章进行思考、记录,那就是渲染到何处。
WebGL 的上下文对象是与 canvas 元素强关联的,没有 canvas 创建不了上下文,也就是说,WebGL 在设计之初就是拿来绘图的(的确如此),没考虑 GPU 的其它功能,后来才逐渐加入其它功能。所以说,WebGL 若不显式指定 Framebuffer,那默认就是画到 canvas 自己身上。
WebGPU 则更强调“GPU”本身,它是需要自己制定绘制目标的,也就是在通道编码器中设置的颜色附件关联的纹理对象。
本篇着重介绍 WebGPU 这一处新设计。有关 FBO 和 RBO 技术与 WebGPU 的差异我另有文章,请自行查阅。
把帧缓冲映射到绘图窗口,就算完成了。WebGL 需要使用 gl.viewport() 来指定绘图区的大小:
gl.viewport(0, 0, canvas.width, canvas.height)
通常就是 canvas 的像素长宽(而不是 CSS 长宽)。
一般页面变化时要修改:
const resize = (canvas) => {
// 获取 css 实际渲染尺寸
const displayWidth = canvas.clientWidth;
const displayHeight = canvas.clientHeight;
// 检查尺寸是否相同
if (canvas.width != displayWidth || canvas.height != displayHeight) {
// 设置为相同的尺寸
canvas.width = displayWidth;
canvas.height = displayHeight;
}
}
const frame = () => {
// ...
resize(gl.canvas)
gl.viewport(0, 0, gl.canvas.width, gl.canvas.height)
}
你可以获取当前机器上的最大视口:
gl.getParameter(gl.MAX_VIEWPORT_DIMS)
也可以获取当前的视口大小:
gl.getParameter(gl.VIEWPORT)
扩展知识:ThreeJS 对尺寸变化的处理方式是修改 renderer 的 size,以及修改 camera 的宽高比并更新投影矩阵。
在一个常规的 WebGPU 渲染程序中,如果要显式绘制到 canvas 上,那就要让 canvas 作为一张纹理,附着到渲染通道的颜色附件上。
// 这一步在请求设备对象之后就可以进行了
const context = canvasRef.current.getContext('webgpu');
const presentationFormat = context.getPreferredFormat(adapter)
const devicePixelRatio = window.devicePixelRatio || 1
const presentationSize = [
canvasRef.current.clientWidth * devicePixelRatio,
canvasRef.current.clientHeight * devicePixelRatio,
]
// 使用设备对象配置 canvas,让它变成合适的纹理
context.configure({
device,
format: presentationFormat,
size: presentationSize,
})
然后在渲染通道编码器就可以用 canvas 这个纹理了:
const frame = () => {
// ...
// 渲染的每一帧,获取新的纹理和视图绑定至渲染通道
const textureView = context.getCurrentTexture().createView()
const renderPassDescriptor = {
colorAttachments: [
{
view: textureView,
loadValue: { r: 0.0, g: 0.0, b: 0.0, a: 1.0 },
storeOp: 'store',
},
],
}
// ... draw
requestAnimationFrame(frame)
}
也许你会问,为什么要这么复杂?这跟 WebGPU 的使命有关,前面说了,WebGPU 更专注于 GPU 本身,而不是一个简单的绘图 API,在 WebGPU 中,渲染绘图不再是第一优先级,调用 WebGPU 的最大意义就是可以通过统一的 API 访问 GPU 的计算核心。
每当调用 configure() 方法去配置 canvas 纹理时,先前的纹理对象就会被销毁,并重新生成一个,适合窗口缩放时进行。
当然,你也可以使用 context.unconfigure() 方法仅取消配置,不再生成纹理。
同一个配置前提下,getCurrentTexture() 返回的纹理总是同一个。
如果你补显式指定配置参数的 size,那么内部会默认使用 canvas 的绘图长宽。如果你设置的长宽与 canvas 的绘图长宽不一致,那么它会帮你缩放到 canvas 的长宽。
改变 canvas 的大小,可以是改变其 CSS 渲染大小,也可以改变它的绘制长宽。
规范给了一个简单的例子,使用 ResizeObserver API 来监听 canvas 的大小,并重新配置 canvas 纹理:
const canvas = document.createElement('canvas')
const context = canvas.getContext('webgpu')
const resizeObserver = new ResizeObserver(entries => {
for (const entry of entries) {
// 跳过非 canvas 目标
if (entry.target != canvas) {
continue
}
// 为 webgpu 重新配置 canvas 纹理
context.configure({
device: gpuDevice,
format: context.getPreferredFormat(gpuAdapter),
size: {
// 获取到新的长宽
width: entry.devicePixelContentBoxSize[0].inlineSize,
height: entry.devicePixelContentBoxSize[0].blockSize,
}
})
}
})
// 仅观察 canvas
resizeObserver.observe(canvas)
图形编程中的纹理,是一个很大的话题,涉及到的知识面非常多,有硬件的,也有软件的,有实时渲染技术,也有标准的实现等非常多可以讨论的。
受制于个人学识浅薄,本文只能浅表性地列举 WebGL 和 WebGPU 中它们创建、数据传递和着色器中大致的用法,格式差异,顺便捞一捞压缩纹理的资料。
创建纹理对象 texture,并将其绑定:
const texture = gl.createTexture()
gl.bindTexture(gl.TEXTURE_2D, texture)
此时这个对象只是一个空的 WebGLTexture,还没有发生数据传递。
WebGL 没有采样器 API,纹理采样参数的设置是通过调用 gl.texParameteri() 方法完成的:
gl.texParameteri(gl.TEXTURE_2D, gl.TEXTURE_WRAP_S, gl.CLAMP_TO_EDGE)
gl.texParameteri(gl.TEXTURE_2D, gl.TEXTURE_WRAP_T, gl.CLAMP_TO_EDGE)
gl.texParameteri(gl.TEXTURE_2D, gl.TEXTURE_MIN_FILTER, gl.NEAREST)
gl.texParameteri(gl.TEXTURE_2D, gl.TEXTURE_MAG_FILTER, gl.NEAREST)
采样参数是 gl.TEXTURE_WRAP_S、gl.TEXTURE_WRAP_T、gl.TEXTURE_MIN_FILTER、gl.TEXTURE_MAG_FILTER,这四个采样参数的值分别是 gl.CLAMP_TO_EDGE、gl.CLAMP_TO_EDGE、gl.NEAREST、gl.NEAREST,具体含义就不细说了,我认为这方面的资料还是蛮多的。
首先,是纹理数据的写入。
使用 gl.texImage2D() 方法将内存中的数据写入至纹理中,流向是 CPU → GPU:
gl.texImage2D(gl.TEXTURE_2D, 0, gl.RGBA, gl.RGBA, gl.UNSIGNED_BYTE, image)
这个函数有非常多种重载,可以自行查阅 MDN 或 WebGL 有关规范。
上述函数调用传递的 image 是 Image 类型的,也即 HTMLImageElement;其它的重载可以使用的数据来源还可以是:
ArrayBufferView:Uint8Array、Uint16Array、Uint32Array、Float32ArrayImageDataHTMLImageElement/HTMLCanvasElement/HTMLVideoElementImageBitmap不同数据来源有对应的数据写入方法。
其次,是纹理的拷贝。
WebGL 2.0 使用 gl.blitFramebuffer() 方法,以帧缓冲对象为媒介,拷贝附着在两类附件上的关联纹理对象。
下面为拷贝 renderableFramebuffer 的颜色附件的简单示例代码:
const renderableFramebuffer = gl.createFramebuffer();
const colorFramebuffer = gl.createFramebuffer();
// ... 一系列绑定和设置 ...
gl.bindFramebuffer(gl.READ_FRAMEBUFFER, renderableFramebuffer);
gl.bindFramebuffer(gl.DRAW_FRAMEBUFFER, colorFramebuffer);
// ... 执行绘制 ...
gl.blitFramebuffer(
0, 0, FRAMEBUFFER_SIZE.x, FRAMEBUFFER_SIZE.y,
0, 0, FRAMEBUFFER_SIZE.x, FRAMEBUFFER_SIZE.y,
gl.COLOR_BUFFER_BIT, gl.NEAREST
);
WebGL 2.0 允许将 FBO 额外绑定到可读帧缓冲(gl.READ_FRAMEBUFFER)或绘制帧缓冲(gl.DRAW_FRAMEBUFFER),WebGL 1.0 只能绑定至单个帧缓冲 gl.FRAMEBUFFER.
WebGL 1.0 没那么便利,就只能自己封装比较麻烦一点的做法了,提供如下思路:
WebGLProgram 把源纹理通过着色器渲染进 FBOgl.copyTexImage2D() 或 gl.copyTexSubImage2D() 方法拷贝到目标纹理gl.readPixels() 读取渲染结果,然后使用 gl.texImage2D() 将像素数据写入目标纹理(这个方法看起来很蠢,虽然技术上行得通)如何在片元着色器代码中对纹理进行采样,获取该顶点对应的纹理颜色呢?
很简单,获取顶点着色器发送过来的插值后的片元纹理坐标 v_texCoord,然后对纹理对象进行采样即可。
uniform sampler2D u_textureSampler;
varying vec2 v_texCoord;
void main() {
gl_FragColor = texture2D(u_textureSampler, v_texCoord);
}
关于如何通过 uniform 传递纹理到着色器中,还请查阅我之前发过的 Uniform 一文。
很多国内外的文章有介绍这两个东西,它们通常出现在离屏渲染容器 - 帧缓冲对象的关联附件上。
感兴趣 FBO / RBO 主题的可以翻翻我不久之前的文章。
纹理与渲染缓冲,即 WebGLTexture 和 WebGLRenderbuffer,其实最大的区别就是纹理允许再次通过 uniform 的形式传给下一个渲染通道的着色器,进行纹理采样。有资料说这两个是存在性能差异的,但是我认为那点差异还不如认真设计好架构。
这东西虽然是给立方体的六个面贴图用的“特殊”纹理,但是非常合适做环境贴图,对应的数据传递函数、着色器采样函数都略有不同。
// 注意第一个参数,既然有 6 面,就有六个值,这里是 X 轴正方向的面
gl.texImage2D(
gl.TEXTURE_CUBE_MAP_POSITIVE_X,
0,
gl.RGBA,
gl.RGBA,
gl.UNSIGNED_BYTE,
imagePositiveX)
// 为立方体纹理创建 Mipmap
gl.generateMipmap(gl.TEXTURE_CUBE_MAP)
// 设置采样参数
gl.texParameteri(
gl.TEXTURE_CUBE_MAP,
gl.TEXTURE_MIN_FILTER,
gl.LINEAR_MIPMAP_LINEAR)
在着色器中:
// 顶点着色器
attribute vec4 a_position;
uniform mat4 u_vpMatrix;
varying vec3 v_normal;
void main() {
gl_Position = u_vpMatrix * a_position;
// 因为位置是以几何中心为原点的,可以用顶点坐标作为法向量
v_normal = normalize(a_position.xyz);
}
// 片元着色器
precision mediump float; // 从顶点着色器传入
varying vec3 v_normal; // 纹理
uniform samplerCube u_texture;
void main() {
gl_FragColor = textureCube(u_texture, normalize(v_normal));
}
这方面资料其实也不少,网上搜索可以轻易找到。
WebGL 2.0 增加了若干内容,资料可以在 WebGL2Fundamentals 找到,这里简单列举。
textureSize() 函数获取纹理大小texelFetch() 直接获取指定坐标的纹素WebGLSampler 对象的支持除此之外,GLSL 升级到 300 后,原来的 texture2D() 和 textureCube() 纹理采样函数全部改为了 texture() 函数,详见文末参考资料的迁移文章。
裁剪空间里的顶点构成的形状,其实是近大远小的,这点没什么问题。对于远处的物体,透视投影变换完成后会比较小,这就没必要对这个“小”的部分使用“大”的部分一样清晰的纹理了。
Mipmap 能解决这个问题,幸运的是,WebGL 只需简单的方法调用就可以创建 Mipmap,无需操心太多。
gl.generateMipmap(gl.TEXTURE_2D)
在参考资料中,你可以在 《WebGL纹理详解之三:纹理尺寸与Mipmapping》一文中见到不错的解释,还可以看到 gl.texImage2D() 的第二个参数 level 的具体用法。
WebGPU 将纹理分成 GPUTexture 与 GPUTextureView 两种对象。
调用 device.createTexture() 即可创建一个纹理对象,你可以通过传参指定它的用途、格式、维度等属性。它扮演的更多时候是一个数据容器,也就是纹素的容器。
// 普通贴图
const texture = device.createTexture({
size: [512, 512, 1],
format: 'rgba8unorm',
usage: GPUTextureUsage.TEXTURE_BINDING
| GPUTextureUsage.COPY_DST
| GPUTextureUsage.RENDER_ATTACHMENT,
})
// 深度纹理
const depthTexture = device.createTexture({
size: [800, 600],
format: 'depth24plus',
usage: GPUTextureUsage.RENDER_ATTACHMENT,
})
// 从 canvas 中获取纹理
const gpuContext = canvas.getContext('webgpu')
const canvasTexture = gpuContext.getCurrentTexture()
上面介绍了三种创建纹理的方式,前两种类似,格式和用途略有不同;最后一个是来自 Canvas 的。
注意一点,有一些纹理格式并不是默认就支持的。如果需要特定格式,有可能还要在请求设备对象时,附上功能列表(
requiredFeatures)
知道创建纹理对象,还要知道如何往其中写入来自 JavaScript 运行时的图像资源。
首先,介绍纹理数据写入。
有两个手段可以向纹理对象写入数据:
ImageBitmap API(globalThis.createImageBitmap())对于第一种,使用队列对象的 copyExternalImageToTexture() 方法,配合浏览器自带的 API,在队列时间轴上完成外部数据拷入纹理对象:
const diffuseTexture = device.createTexture({ /* ... */ })
/** 方法一 借助 HTMLImageElement 解码 **/
const img = document.createElement('img')
img.src = require('/assets/diffuse.png')
await img.decode()
const imageBitmap = await createImageBitmap(img)
/** 方法一 **/
/** 方法二 使用 Blob **/
const blob = await fetch(url).then((r) => r.blob())
const imageBitmap = await createImageBitmap(blob)
/** 方法二 **/
device.queue.copyExternalImageToTexture(
{ source: imageBitmap },
{ texture: diffuseTexture },
[imageBitmap.width, imageBitmap.height]
)
上述例子提供了两种思路,第一种借助浏览器的 img 元素,也即 Image 来完成图像的网络请求、解码;第二种借助 Blob API;随后,使用 Image(HTMLImageElement)/Blob 对象创建一个 ImageBitmap,并进入队列中完成数据拷贝。
对于第二种,使用队列对象的 writeTexture() 方法,在队列时间轴上完成外部数据拷入纹理对象:
const imgRGBAUint8Array = await fetchAndParseImageToRGBATypedArray('/assets/diffuse.png')
const arrayBuffer = imgRGBAUint8Array.buffer
device.queue.writeTexture(
{
bytePerRow: 4 * 512, // 每行多少字节
rowsPerImage: 512 // 这个图像有多少行
},
arrayBuffer,
{ texture: diffuseTexture },
[512, 512, 1]
)
第二种方法相对来说比较消耗性能,因为需要浏览器 API(例如借助 canvas 绘图再取数据)或其它手段(如 wasm 等)解码图像二进制至 RGBA 数组,不太适合每帧操作。
其次,介绍纹理拷贝。
与 WebGL 需要使用 FBO 或重新渲染不同,WebGPU 原生就在指令编码器上提供了纹理复制操作有关的 API:使用 commandEncoder.copyTextureToTexture() 可以完成纹理之间的拷贝,使用 commandEncoder.copyBufferToTexture()、commandEncoder.copyTextureToBuffer() 可以在缓冲对象和纹理对象之间的拷贝(以便读取纹素数据)。
以纹理间的拷贝为例:
commandEncoder.copyTextureToTexture({
texture: mipmapTexture,
mipLevel: 4,
}, {
texture: destTexture,
mipLevel: 5,
}, [512, 512, 1])
这个例子将 Mipmap 纹理的第 4 级拷贝至目标纹理对象的第 5 级,纹理的大小是 512 × 512,需要注意 mipmapTexture 和 destTexture 的 usage,复制源需要有 GPUTextureUsage.COPY_SRC,复制目标要有 GPUTextureUsage.COPY_DST.
既然发生在指令编码器上,那就意味着操作纹理时,与普通的渲染通道、计算通道是平级的 —— 换句话说,拷贝纹理的行为,必须在渲染通道之前或之后进行。
因官方文档在我写这篇文章前,都没有给出纹理视图对象的描述,所以下面的描述是我根据 WebGPU 中关于纹理方面的 API 猜测的。
当 CPU 需要使用纹理时,譬如进行纹理数据的写入,或者纹理对象之间的拷贝,会直接在队列上进行,而且传参给的就是 GPUTexture 本身;而 GPU 需要使用纹理时,例如资源绑定组绑定一个纹理,或者渲染通道的附件需要使用容器时,通常传参给的是 GPUTextureView;所以,我猜测:
创建纹理视图其实很简单,它通过调用纹理对象本身的 createView() 方法创建:
const view = texture.createView()
// 在渲染通道的颜色附件中
const renderPassDescriptor = {
colorAttachments: [
{
view: canvasTexture.createView(),
// ...
}
]
}
纹理视图对象是可以传递参数对象的,类型是 GPUTextureViewDescriptor,当然这个参数对象是可选的。这个参数对象可以更具体描述纹理视图。
譬如,立方体纹理创建视图时,需要明确指定其维度(dimension)参数等参数:
const cubeTextureView = cubeTexture.createView({
dimension: 'cube',
arrayLayerCount: 6,
})
与 WebGL 使用的阉割版 GLSL 相比,WGSL 提供的类型就多多了。
WebGL 1.0 中的采样参数与 WebGL 2.0 姗姗来迟的 WebGLSampler 类型,在 WebGPU 和 WGSL 中统一为具体的变量类型,即 WebGPU 对应 GPUSampler,WGSL 对应 sampler 和 sampler_comparision 类型。
WGSL 中的纹理类型有十几种,纹理类型与纹理视图的 dimension 参数是紧密相关的,参考 WebGPU Spec - TextureView Creation
而纹理相关的函数也跟随着增多了许多,且各有用途,有最常规的纹理采样函数 textureSample,读取单个纹素的 textureLoad 函数,获取纹理尺寸的 textureDimensions(等价于 WebGL 2.0 的 textureSize),向存储型纹理写纹素的 textureStore 等,每个函数又有若干种重载。
最基本的用法,使用二维 f32 纹理对象、采样器、纹理坐标进行采样:
@group(0) @binding(1) var mySampler: sampler;
@group(0) @binding(2) var myTexture: texture_2d<f32>;
@stage(fragment)
fn main(@location(0) fragUV: vec2<f32>) -> @location(0) vec4<f32> {
return textureSample(myTexture, mySampler, fragUV);
}
鉴于纹理技术本身的复杂性,官方在 GitHub issue 386 中关于自动生成 Mipmap 的 API 有激烈的讨论,目前倾向于不实现,把 Mipmap 的生成实现交给社区。
WebGPU 保留了 Mipmap 的支持,但是没有像 WebGL 一样提供简便的 gl.generateMipmap(gl.TEXTURE_2D) 调用方法一键生成,需要自己对纹理的每一个层生成。
幸运的是,WebGPU 社区的 Toji 大佬编写了一个工具来生成纹理的 Mipmap:web-texture-tool/src/webgpu-mipmap-generator.js,原理就是开辟一个新的指令编码器,使用一条特定的渲染管线离屏计算每一级 mipmap,最终写入一个纹理对象并返回。若源纹理具备渲染附件的用途(GPUTextureUsage.RENDER_ATTACHMENT),那么就在源纹理上生成,否则会使用 commandEncoder.copyTextureToTexture() 方法把工具类内部创建的临时 mipmap 纹理对象拷贝到源纹理对象。
目前只能对 "2d" 类型的纹理起作用,这个类的简单用法如下:
import { WebGPUMipmapGenerator } from 'web-texture-tool/webgpu-mipmap-generator.js'
/* -- 常规创建纹理 -- */
const textureDescriptor = { /**/ }
const srcTexture = device.createTexture(textureDescriptor)
/* -- 为纹理创建 mipmap -- */
const mipmapGenerator = new WebGPUMipmapGenerator(device)
mipmapGenerator.generateMipmap(srcTexture, textureDescriptor)
// ...
generateMipmap() 方法执行后,将在 2d 纹理的每个 layer 创建完成每一层 Mipmap,顺带一提,这个工具并未完全稳定,请考虑各种风险。
注意一点,这个 textureDescriptor 的 mipLevelCount 是有一个 算法 的,它必须小于等于根据纹理维度、纹理尺寸计算的 最大限制值。这里纹理维度是 2d 类型,最大尺寸是 64,那么容易算得最大 mipLevel 是 Math.floor(Math.log2(64)) + 1 = 7.
const textureDescriptor = {
// ...
mipLevelCount: 7, // 创建纹理时,允许人为指定 mipmap 有多少级,但是不超最大限制
size: {
width: 64,
height: 64,
depthOrArrayLayers: 1
},
dimension: "2d"
}
扩展阅读:ThreeJS 关于 WebGPU 这项议程,参考了 Toji 的工具,集成到
WebGPUTextureUtils类,有关讨论见 ThreeJS pull 20284 WebGPUTextures: Add support for mipmap computation.
涉及到压缩纹理格式我更是只能“纸上谈兵”,这一段仅作为个人知识浅表性的记录,道阻且长...
这一小节其实与 WebGL、WebGPU 的接口并无太大关系,纹理压缩算法,或者说压缩纹理格式,是另外的一门技术,WebGL 和 WebGPU 在底层实现上做了支持。
简单的说,压缩纹理格式是一种“时间+空间换空间”的产物,需要提前生成,常见的封装文件格式有 ktx2 等(就好比 h264/5 于 .mp4)。它有效地节约了 GPU 显存,并且解压速度比传统的 Web 图像格式 jpg、png 更快,它本身也比 jpg/png 的文件体积要小一些。
不过很遗憾的是,诸多压缩编码算法在各个软硬件厂商的实现都不太一样,没法像 jpg/png 一样广泛、普遍使用。
为了兼容性,通常会针对不同平台生成不同的压缩纹理备用,也就是所谓的“时间+空间换解压时间+显存空间”。
WebGL 1.0 只能使用 2D 纹理,WebGL 2.0 支持使用 3D 纹理,而且对压缩纹理的使用,是需要借助扩展项来完成的。例如:
const ext = (
gl.getExtension('WEBGL_compressed_texture_s3tc') ||
gl.getExtension('MOZ_WEBGL_compressed_texture_s3tc') ||
gl.getExtension('WEBKIT_WEBGL_compressed_texture_s3tc')
)
const texture = gl.createTexture()
gl.bindTexture(gl.TEXTURE_2D, texture)
gl.compressedTexImage2D(gl.TEXTURE_2D, 0, ext.COMPRESSED_RGBA_S3TC_DXT5_EXT, 512, 512, 0, textureData)
gl.texParameteri(gl.TEXTURE_2D, gl.TEXTURE_MAG_FILTER, gl.LINEAR)
gl.texParameteri(gl.TEXTURE_2D, gl.TEXTURE_MIN_FILTER, gl.LINEAR)
这个示例代码展示了在 WebGL 1.0 通过 compressedTexImage2D() 方法使用了一个 S3TC_DXT5 压缩编码的纹理数据 textureData.
具体的 WebGL 1/2 压缩扩展和用法参考 MDN - compressedTexImage[23]D()
对于 WebGPU,它支持三类压缩格式:
请求设备对象时传入 requiredFeatures 即可请求所需压缩纹理格式:
// 以 astc 格式为例 -- 需要在适配器上判断是否支持此格式
const requiredFeatures = []
if (gpuAdapter.features.has('texture-compression-astc')) {
requiredFeatures.push('texture-compression-astc')
}
const device = await adapter.requestDevice({
requiredFeatures
})
当适配器支持时即可请求。这样,astc 族压缩纹理格式就全部可用了:
const compressedTextureASTC = device.createTexture({
// ...
format: "astc-10x6-unorm-srgb"
})
三大类型的压缩纹理格式支持列表参考 WebGPU Spec - Feature Index: 24.4, 24.5, 24.6
幸运的是,Toji 的库 toji/web-texture-tool 也为纹理的加载写了两种 Loader,用于 WebGL 和 WebGPU 中纹理数据的生成,支持压缩格式。
纹理压缩算法(格式)简单记忆规则:
ETC1/2 - AndroidDXT/S3TC - WindowsPVRTC - AppleASTC - Will Be The Future详细的资料在文末的参考资料里了。
关于 Mipmap、级联纹理、压缩格式等进阶知识,我觉得已经超出了这两个 API 比对的范围,况且个人理解尚不深,就不关公面前舞大刀了。
这篇与上篇相隔时间较长,我在学习的过程中补充了很多欠缺的知识,为了严谨和准确性也查阅了不少的例子、啃了不少的源码。
简而言之,WebGPU 把 WebGL 1/2 两代的纹理接口进行了科学统一,并且出厂自带压缩纹理格式的支持(当然,还是看具体平台的,需要按需选取)。
其中最让我感兴趣的就是 WebGPU 对纹理的二级细化,提供 GPUTexture 和 GPUTextureView 两级 API,发文时还未见到官方规范解释这两个 API,猜测前者专注于数据的 IO,后者则提供纹理数据的一层视图(根据参数具象化纹理数据的某一方面)。
很遗憾,发文时我还没深入了解过存储型纹理,以后介绍 GPGPU 时再说吧。
众所周知,在 GPU 跑可编程管线的时候,着色器是并行运行的,每个着色器入口函数都会在 GPU 中并行执行。每个着色器对一大片统一格式的数据进行冲锋,体现 GPU 多核心的优势,可以小核同时处理数据;不过,有的数据对每个着色器都是一样的,这种数据的类型是“uniform”,也叫做统一值。
这篇文章罗列了原生 WebGL 1/2 中的 uniform 资料,以及 WebGPU 中的 uniform 资料,有一些例子供参考,以用来比对它们之间的差异。
在 WebGL 1.0 中,通常是在 JavaScript 端保存 WebGLUniformLocation 以向着色器程序传递 uniform 值的。
使用 gl.getUniformLocation() 方法获取这个 location,有如下几种方式
gl.getUniformLocation(program, 'u_someUniformVar')gl.getUniformLocation(program, 'u_someVec3[0]') 是获取第 0 个元素(元素类型是 vec3)的 locationgl.getUniformLocation(program, 'u_someStruct.someMember')上面三种情况与之对应的着色器代码:
// 全名
uniform float u_someUniformVar;
// 分量
uniform vec3 u_someVec3[3]; // 注意,这里是 3 个 vec3
// 结构体成员
struct SomeStruct {
bool someMember;
};
uniform SomeStruct u_someStruct;
传值分三类,标量/向量、矩阵、采样纹理,见下文。
对于矩阵,使用 gl.uniformMatrix[234]fv() 方法即可传递,其中,f 代表 float,v 代表 vector,即传入参数要是一个向量(即数组);
以传递一个 4×4 的矩阵为例:
// 获取 location(初始化时)
const matrixLocation = gl.getUniformLocation(program, "u_matrix")
// 创建或更新列主序变换矩阵(渲染时)
const matrix = [/* ... */]
// 传递值(渲染时)
gl.uniformMatrix4fv(matrixLocation, false, matrix)
对于普通标量和向量,使用 gl.uniform[1234][fi][v]() 方法即可传递,其中,1、2、3、4 代表标量或向量的维度(1就是标量啦),f/i 代表 float 或 int,v 代表 vector(即你传递的数据在着色器中将解析为向量数组)。
举例:
gl.uniform1fv(someFloatLocation, [4.5, 7.1])gl.uniform4i(someIVec4Location, 5, 2, 1, 3)gl.uniform4iv(someIVec4Location, [5, 2, 1, 3, 2, 12, 0, 6])gl.uniform3f (someVec3Location, 7.1, -0.8, 2.1)上述 4 个赋值语句对应的着色器中的代码为:
// 语句 1 可以适配 1~N 个浮点数
// 只传单元素数组时,可直接声明 uniform float u_someFloat;
uniform float u_someFloat[2];
// 语句 2 适配一个 ivec4
uniform ivec4 u_someIVec4;
// 语句 3 适配 1~N 个 ivec4
// 只传单元素数组时,可直接声明 uniform float u_someIVec4;
uniform ivec4 u_someIVec4[2];
// 语句 4 适配一个 vec3
uniform vec3 u_someVec3;
到了 WebGL 2.0,在组分值类型会有一些扩充,请读者自行查阅相关文档。
在顶点着色器阶段,可以使用顶点的纹理坐标对纹理进行采样:
attribute vec3 a_pos;
attribute vec2 a_uv;
uniform sampler2D u_texture;
varying vec4 v_color;
void main() {
v_color = texture2D(u_texture, a_uv);
gl_Position = a_pos; // 假设顶点不需要变换
}
那么,在 JavaScript 端,可以使用 gl.uniform1i() 来告诉着色器我把纹理刚刚传递到哪个纹理坑位上了:
const texture = gl.createTexture()
const samplerLocation = gl.getUniformLocation(/* ... */)
// ... 设置纹理数据 ...
gl.activeTexture(gl[`TEXTURE${5}`]) // 告诉 WebGL 使用第 5 个坑上的纹理
gl.bindTexture(gl.TEXTURE_2D, texture)
gl.uniform1i(samplerLocation, 5) // 告诉着色器待会读纹理的时候去第 5 个坑位读
WebGL 2.0 的 Uniform 系统对非方阵类型的矩阵提供了支持,例如
const mat2x3 = [
1, 2, 3,
4, 5, 6,
]
gl.uniformMatrix2x3fv(loc, false, mat2x3)
上述方法传递的是 4×3 的矩阵。
而对于单值和向量,额外提供了无符号数值的方法,即由 uniform[1234][fi][v] 变成了 uniform[1234][f/ui][v],也就是下面 8 个新增方法:
gl.uniform1ui(/* ... */) // 传递数据至 1 个 uint
gl.uniform2ui(/* ... */) // 传递数据至 1 个 uvec2
gl.uniform3ui(/* ... */) // 传递数据至 1 个 uvec3
gl.uniform4ui(/* ... */) // 传递数据至 1 个 uvec4
gl.uniform1uiv(/* ... */) // 传递数据至 uint 数组
gl.uniform2uiv(/* ... */) // 传递数据至 uvec2 数组
gl.uniform3uiv(/* ... */) // 传递数据至 uvec3 数组
gl.uniform4uiv(/* ... */) // 传递数据至 uvec4 数组
对应 GLSL300 中的 uniform 为:
#version 300 es
#define N ? // N 取决于你的需要,JavaScript 传递的数量也要匹配
uniform uint u_someUint;
uniform uvec2 u_someUVec2;
uniform uvec3 u_someUVec3;
uniform uvec4 u_someUVec4;
uniform uint u_someUintArr[N];
uniform uvec2 u_someUVec2Arr[N];
uniform uvec3 u_someUVec3Arr[N];
uniform uvec4 u_someUVec4Arr[N];
需要额外注意的是,uint/uvec234 这些类型在高版本的 glsl 才能使用,也就是说不向下兼容 WebGL 1.0 及 GLSL100.
然而,WebGL 2.0 带来的不单单只是这些小修小补,最重要的莫过于 UBO 了,马上开始。
在 WebGL 1.0 的时候,任意种类的统一值一次只能设定一个,如果一帧内 uniform 有较多更新,对于 WebGL 这个状态机来说不是什么好事,会带来额外的 CPU 至 GPU 端的传递开销。
在 WebGL 2.0,允许一次发送一堆 uniform,这一堆 uniform 的聚合体,就叫做 UniformBuffer,具体到代码中:
先是 GLSL 300
uniform Light {
highp vec3 lightWorldPos;
mediump vec4 lightColor;
};
然后是 JavaScript
const lightUniformBlockBuffer = gl.createBuffer()
const lightUniformBlockData = new Float32Array([
0, 10, 30, 0, // vec3, 光源位置, 为了 8 Byte 对齐填充一个尾 0
1, 1, 1, 1, // vec4, 光的颜色
])
gl.bindBuffer(gl.UNIFORM_BUFFER, lightUniformBlockBuffer);
gl.bufferData(gl.UNIFORM_BUFFER, lightUniformBlockData, gl.STATIC_DRAW);
gl.bindBufferBase(gl.UNIFORM_BUFFER, 0, lightUniformBlockBuffer)
先别急着问为什么,一步一步来。
首先你看到了,在 GLSL300 中允许使用类似结构体一样的块状语法声明多个 Uniform 变量,这里用到了光源的坐标和光源的颜色,分别使用了不同的精度和数据类型(vec3、vec4)。
随后,在 JavaScript 端,你看到了用新增的方法 gl.bindBufferBase() 来绑定一个 WebGLBuffer 到 0 号位置,这个 lightUniformBlockBuffer 其实就是集合了两个 Uniform 变量的 UniformBufferObject (UBO),在着色器中那块被命名为 Light 的花括号区域,则叫 UniformBlock.
其实,创建一个 UBO 和创建普通的 VBO 是一样的,绑定、赋值操作也几乎一致(第一个参数有不同)。只不过 UBO 可能更需要考虑数值上的设计,例如 8 字节对齐等,通常会在设计着色器的时候把相同数据类型的 uniform 变量放在一起,达到内存使用上的最佳化。
在 WebGL 2.0 中,JavaScript 端允许你把着色器程序中的 UniformBlock 位置绑定到某个变量中:
const viewUniformBufferIndex = 0;
const materialUniformBufferIndex = 1;
const modelUniformBufferIndex = 2;
const lightUniformBufferIndex = 3;
gl.uniformBlockBinding(prg, gl.getUniformBlockIndex(prg, 'View'), viewUniformBufferIndex);
gl.uniformBlockBinding(prg, gl.getUniformBlockIndex(prg, 'Model'), modelUniformBufferIndex);
gl.uniformBlockBinding(prg, gl.getUniformBlockIndex(prg, 'Material'), materialUniformBufferIndex);
gl.uniformBlockBinding(prg, gl.getUniformBlockIndex(prg, 'Light'), lightUniformBufferIndex);
这里,使用的是 gl.getUniformBlockIndex() 获取 UniformBlock 在着色器程序中的位置,而把这个位置绑定到你喜欢的数字上的是 gl.uniformBlockBinding() 方法。
这样做有个好处,你可以在你的程序里人为地规定各个 UniformBlock 的顺序,然后用这些 index 来更新不同的 UBO.
// 使用不同的 UBO 更新 materialUniformBufferIndex (=1) 指向的 UniformBlock
gl.bindBufferBase(gl.UNIFORM_BUFFER, 1, redMaterialUBO)
gl.bindBufferBase(gl.UNIFORM_BUFFER, 1, greenMaterialUBO)
gl.bindBufferBase(gl.UNIFORM_BUFFER, 1, blueMaterialUBO)
当然,WebGL 2.0 对 Uniform 还有别的扩充,此处不再列举。
bindBufferBase 的作用类似于 enableVertexAttribArray,告诉 WebGL 我马上就要用哪个坑了。
着色器使用 GLSL300 语法才能使用 UniformBlock 和 新的数据类型,除此之外和 GLSL100 没啥区别。当然,GLSL300 有很多新语法,这里只捡一些关于 Uniform 的来写。
关于 uint/uvec234 类型,在 2.1 节已经有例子了,这里不赘述。
而关于 UniformBlock,还有一点需要补充的,那就是“命名”问题。
UniformBlock 的语法如下:
uniform <BlockType> {
<BlockBody>
} ?<blockName>;
// 举例:具名定义
uniform Model {
mat4 world;
mat4 worldInverseTranspose;
} model;
// 举例:不具名定义
uniform Light {
highp vec3 lightWorldPos;
mediump vec4 lightColor;
};
如果使用具名定义,那么访问 Block 内的成员就需要使用它的 name 了,例如 model.world、model.worldInverseTranspose 等。
举完整的例子如下:
#version 300 es
precision highp float;
precision highp int;
// uniform 块的布局控制
layout(std140, column_major) uniform;
// 声明 uniform 块:Transform,命名为 transform 供主程序使用
// 也可以不命名,就直接用 mvpMatrix 即可
uniform Transform
{
mat4 mvpMatrix;
} transform;
layout(location = 0) in vec2 pos;
void main() {
gl_Position = transform.mvpMatrix * vec4(pos, 0.0, 1.0);
}
注意,即使给 UniformBlock 命名为 transform,但是立面的 mvpMatrix 是不能与其它 Block 里面的成员共名的,transform 没有命名空间的作用。
再看 JavaScript:
//#region 获取着色器程序中的 uniform 位置并绑定
const uniformTransformLocation = gl.getUniformBlockIndex(program, 'Transform')
gl.uniformBlockBinding(program, uniformTransformLocation, 0)
//endregion
//#region 创建 ubo
const uniformTransformBuffer = gl.createBuffer()
//#endregion
//#region 创建矩阵所需的 ArrayBufferView,列主序
const transformsMatrix = new Float32Array([
1.0, 0.0, 0.0, 0.0,
0.0, 1.0, 0.0, 0.0,
0.0, 0.0, 1.0, 0.0,
0.0, 0.0, 0.0, 1.0
])
//#endregion
//#region 传递数据给 WebGLBuffer
gl.bindBuffer(gl.UNIFORM_BUFFER, uniformTransformBuffer)
gl.bufferData(gl.UNIFORM_BUFFER, transformsMatrix, gl.DYNAMIC_DRAW);
gl.bindBuffer(gl.UNIFORM_BUFFER, null)
//#endregion
// ---------- 在你需要绘制时 ----------
//#region 绑定 ubo 到 0 号索引上的 uniformLocation 以供着色器使用
gl.bindBufferBase(gl.UNIFORM_BUFFER, 0, uniformTransformBuffer)
// ... 渲染
// -------------
纹理与 WebGL 1.0 一致,但是 GLSL300 的纹理函数有变,读者请自行查找资料比对。
WebGPU 有三个类型的 Uniform 资源:标量/向量/矩阵、纹理、采样器。
各自有各自的容器,第一种统一使用 GPUBuffer,也就是所谓的 UBO;第二和第三种使用 GPUTexture 和 GPUSampler.
上述三类资源,把它们通过打成一组,也就是 GPUBindGroup,我叫它资源绑定组,进而传递给组织了着色器模块(GPUShaderModule)的各种管线(GPURenderPipeline、GPUComputePipeline)。
统一起来好办事,这里为节约篇幅,数据传递就不再细说,着重看看它们的打组成绑定组的代码:
const someUbo = device.createBuffer({ /* 注意 usage 要有 UNIFORM */ })
const texture = device.createTexture({ /* 创建常规纹理 */ })
const sampler = device.createSampler({ /* 创建常规采样器 */ })
// 布局对象联系管线布局和绑定组本身
const bindGroupLayout = device.createBindGroupLayout({
entries: [
{
binding: 0, // <- 绑定在 0 号资源
visibility: GPUShaderStage.FRAGMENT,
sampler: {
type: 'filtering'
}
},
{
binding: 1, // <- 绑定在 1 号资源
visibility: GPUShaderStage.FRAGMENT,
texture: {
sampleType: 'float'
}
},
{
binding: 2,
visibility: GPUShaderStage.FRAGMENT,
buffer: {
type: 'uniform'
}
}
]
})
const bindGroup = device.createBindGroup({
layout: bindGroupLayout,
entries: [
{
binding: 0,
resource: sampler, // <- 传入采样器对象
},
{
binding: 1,
resource: texture.createView() // <- 传入纹理对象的视图
},
{
binding: 2,
resource: {
buffer: someUbo // <- 传入 UBO
}
}
]
})
// 管线
const pipelineLayout = device.createPipelineLayout({
bindGroupLayouts: [bindGroupLayout]
})
const renderingPipeline = device.createRenderPipeline({
layout: pipelineLayout
// ... 其它配置
})
// ... renderPass 切换 pipeline 和 bindGroup 进行绘制 ...
更新 Uniform 资源其实很简单。
如果是 UBO,一般会更新前端修改的灯光、材质、时间帧参数以及单帧变化的矩阵等,使用 device.queue.writeBuffer 即可:
device.queue.writeBuffer(
someUbo, // 传给谁
0,
buffer, // 传递 ArrayBuffer,即当前帧中的新数据
byteOffset, // 从哪里开始
byteLength // 取多长
)
使用 writeBuffer 就可以保证用的还是原来创建那个 GPUBuffer,它与绑定组、管线的绑定关系还在;不用映射、解映射的方式传值是减少 CPU/GPU 双端通信成本
如果是纹理,那就用 图像拷贝操作 中的几个方法进行纹理对象更新;
一般不直接对采样器和纹理的更新,而是在编码器上切换不同的绑定组来切换管线所需的资源。尤其是纹理,若频繁更新数据,CPU/GPU 双端通信成本会增加的。
延迟渲染、离屏绘制等需要更新颜色附件的,其实只需要创建新的 colorAttachments 对象即可实现“上一帧绘制的下一帧我能用”,不需要直接从 CPU 内存再刷入数据到 GPU 中。
更新 Uniform 需要对每一帧几乎都要改的、几乎不变的资源进行合理分组,分到不同的绑定组中,这样就可以有针对性地更新,而无需把管线、绑定组重设一次,仅仅在通道编码器上进行切换即可。
此处不涉及太多 WGSL 语法。
与 UniformBlock 类似,需要指定“一块东西”,WGSL 直接使用的结构体。
首先,是 UBO:
// -- 顶点着色器 --
// 声明一个结构体类型
struct Uniforms {
modelViewProjectionMatrix: mat4x4<f32>;
};
// 声明指定其绑定ID是0,绑定组序号是0
@binding(2)
@group(0)
var<uniform> myUniforms: Uniforms;
// —— 然后这个 myUniforms 变量就可以在函数中调用了 ——
然后是纹理和采样器:
@group(0)
@binding(1)
var mySampler: sampler;
@group(0)
@binding(2)
var myTexture: texture_2d<f32>;
// ... 片元着色器主函数中进行纹理采样
textureSample(myTexture, mySampler, fragUV);
WebGL 以 2 为比对基准,它与 WebGPU 相比,没有资源绑定组,没有采样器对象(采样参数通过另外的方法设置)。
比起 WebGPU 的传 descriptor 式的写法,使用一条条方法切换 UniformBlock、纹理等资源可能会有所遗漏,这是全局状态写法的特点之一。当然,上层封装库会帮我们屏蔽这些问题的。
与语法风格相比,其实 WebGPU 改进的更多的是这些 uniform 在每一帧更新时 CPU 到GPU 的负载问题,它是事先由编码器编码成指令缓冲最后一次性发送的,比起 WebGL 一条一条发送是更优的,在图形渲染、GPU运算这种地方,积少成多,性能就高了起来。
关于 WebGL 2.0 的 Uniform 和 GLSL300 我学识不精,若有错误请指出。
前两篇文章介绍了 WebGL 和 WebGPU 是如何准备顶点和数字型 Uniform 数据的(纹理留到下一篇),当渲染所需的原材料准备完成后,就要进入逻辑组装的过程。
WebGL 在这方面通过指定“WebGLProgram”,最终触发“drawArrays”或“drawElements”来启动渲染/计算。全局状态为特征的 WebGL 显然做多步骤渲染来说会麻烦一些,WebGPU 改善了渲染计算过程的接口设计,允许开发者组装更复杂的渲染、计算流程。
以所有的“draw”函数调用为分界线,调用后,就认为 CPU 端的任务已经完成,开始移交准备好的渲染、计算原材料(数据与着色器程序)至 GPU,进而运行起渲染管线,直至输出到帧缓冲/Canvas,我称 draw 这个行为是“一个通道”。
WebGPU 的出现,除了渲染的功能,还出现了通用计算功能,draw 也有了兄弟概念:dispatch(调度),下文会对比介绍。
WebGL 的整个渲染管线(虽然没有管线 API)中,能介入编程的就两处:顶点着色阶段 和片元着色阶段,分别使用顶点着色器和片元着色器完成渲染过程的定制。
很多书或入门教程都会说,顶点着色器和片元着色器是成对出现的,而能管理这两个着色器的上层容器对象,就叫做程序对象(接口 WebGLProgram)。
const vertexShader = gl.createShader(gl.VERTEX_SHADER) // WebGLShader
gl.shaderSource(vertexShader, vertexShaderSource)
gl.compileShader(vertexShader)
const fragmentShader = gl.createShader(gl.FRAGMENT_SHADER) // WebGLShader
gl.shaderSource(fragmentShader, fragmentShaderSource)
gl.compileShader(fragmentShader)
const program = gl.createProgram() // WebGLProgram
gl.attachShader(program, vertexShader)
gl.attachShader(program, fragmentShader)
gl.linkProgram(program)
其实,真正的渲染管线是有很多步骤的,顶点着色和片元着色只是比较有代表性:
既然 WebGL 只能定制这两个阶段,又因为这俩 WebGLShader 是被程序对象(WebGLProgram)管理的,所以,一个程序对象所代表的那个“管线”,通常用于执行一个通道的计算。
在复杂的 Web 三维开发中,一个通道还不足以将想要的一帧画面渲染完成,这个时候要切换着色器程序,再进行 drawArrays/drawElements,绘制下一个通道,这样组合多个通道的绘制结果,就能在一个 requestAnimationFrame 中完成想要的渲染。
上文提及,在一帧的渲染过程中,有可能需要多个通道共同完成渲染。最后一次 gl.drawXXX 的调用会使用一个绘制到目标帧缓冲的 WebGLProgram,这么说可能很抽象,不妨考虑这样一帧的渲染过程:
每一步都需要自己的 WebGLProgram,而且每一步都要全局切换各种 Buffer、Texture、Uniform 的绑定,这样就需要一个封装对象来完成这些状态的切换,可惜的是 WebGL 并没有这种对象,大多数时候是第三方库使用类似的类完成的。
因此,如果你不用第三方库(ThreeJS等),那么你就要考虑设计自己的通道类来管理通道了。
当然,随着现代 GPU 的特性挖掘,一个通道不一定是为了绘制一张“画”,因为有通用计算技术的出现,所以我更乐意称一个通道为“一个计算集合,由一系列计算过程有逻辑地构成”。在 WebGPU 也就是下面要介绍的内容中会提及计算通道,那个就是为通用计算准备的。
在 WebGPU 中,一个计算过程的任务就交由“管线”完成,也就是我们在各种资料里见得到的“可编程管线”的具象化 API;在 WebGPU 中,可编程管线有两类:
GPURenderPipelineGPUComputePipeline管线对象在创建时,会传递一个参数对象,用不同的状态属性配置不同的管线阶段。
回顾,WebGL 是使用
gl.attachShader()方法配置两个 WebGLShader 附着到程序对象上的。
对渲染管线来说,除了可以配置顶点着色器、片元着色器之外,还允许使用其它的状态来配置管线中的其它状态:
GPUPrimitiveState 对象设置 primitive 状态,配置图元的装配阶段和光栅化阶段;GPUDepthStencilState 对象设置 depthStencil 状态,配置深度、模板测试以及光栅化阶段;GPUMultisampleState 对象设置 multisample 状态,配置光栅化阶段中的多重采样。具体内容需要参考 WebGPU 标准的文档。下面举个例子:
const renderPipeline = device.createRenderPipeline({
// --- 布局 ---
layout: pipelineLayout,
// --- 五大状态用于配置渲染管线的各个阶段
vertex: {
module: device.createShaderModule({ /* 顶点着色器参数 */ }),
// ...
},
fragment: {
module: device.createShaderModule({ /* 片元着色器参数 */ }),
// ...
},
primitive: { /* 设置图元状态 */ },
depthStencil: { /* 设置深度模板状态 */ },
multisample: { /* 设置多重采样状态 */ }
})
然后再看一个异步创建计算管线的例子:
const computePipeline = await device.createComputePipelineAsync({
// --- 布局 ---
layout: pipelineLayout,
// --- 计算管线只需配置计算状态 ---
compute: {
module: device.createShaderModule({ /* 计算着色器参数 */ }),
// ...
}
})
读者可自行比对 WebGL 中 WebGLProgram + WebGLShader 的组合。
题外话,我在我的另一文还提到过,管线还具备了 WebGL 中的 VAO 的作用,感兴趣的可以找找看看。管线的片元状态还承担了 MRT 的信息。
由上一小节可知,管线对象收集了对应管线各个阶段所需的参数。这说明了管线是一个具备行为的过程。
光有武林秘籍,没有人练,武功是体现不出来的。
所以,PassEncoder(通道编码器)就起了这么一个作用,它负责记录 GPU 计算一个通道的前后逻辑,可以对其设置管线、顶点相关的缓冲对象、资源绑定组,最后触发计算。
计算通道编码器(GPUComputePassEncoder)的触发动作是调用 dispatch() 方法,这个方法译作“调度”;渲染通道编码器(GPURenderPassEncoder)的触发动作是它的各个 “draw” 方法,即触发绘制。
这个时候就体现出面向对象编程的威力了,你可以将一个通道内的行为(即管线)、数据(即资源绑定组和各种缓冲对象)分别创建,独立于通道编码器之外,这样,面对不同的通道计算时,就可以按需选用不同的管线和数据,进而甚至可以实现管线或者资源的共用。
通道编码器这一小节没有示例代码,示例代码在下一小节。
WebGPU 使用现代图形 API 的思想,将所有 GPU 该做的操作、需要信息事先编码至一个叫“CommandBuffer(指令缓冲)”的容器上,最后统一由 CPU 提交至 GPU,GPU 拿到就吭哧吭哧执行。
编码指令缓冲的对象叫做 GPUCommandEncoder,即指令编码器,它最大的作用就是创建两种通道编码器(commandEncoder.begin[Render/Compute]Pass()),以及发出提交动作(commandEncoder.finish()),最终生成这一帧所需的所有指令。
话不多说,这里直接借用 austin-eng 的例子 ShadowMapping(阴影映射)
// 创建指令编码器
const commandEncoder = device.createCommandEncoder()
{
// 阴影通道的编码过程
const shadowPass = commandEncoder.beginRenderPass(shadowPassDescriptor)
// 使用阴影渲染管线
shadowPass.setPipeline(shadowPipeline)
shadowPass.setBindGroup(0, sceneBindGroupForShadow)
shadowPass.setBindGroup(1, modelBindGroup)
shadowPass.setVertexBuffer(0, vertexBuffer)
shadowPass.setIndexBuffer(indexBuffer, 'uint16')
shadowPass.drawIndexed(indexCount)
shadowPass.endPass()
}
{
// 渲染通道常规操作
const renderPass = commandEncoder.beginRenderPass(renderPassDescriptor);
// 使用常规渲染管线
renderPass.setPipeline(pipeline)
renderPass.setBindGroup(0, sceneBindGroupForRender)
renderPass.setBindGroup(1, modelBindGroup)
renderPass.setVertexBuffer(0, vertexBuffer)
renderPass.setIndexBuffer(indexBuffer, 'uint16')
renderPass.drawIndexed(indexCount)
renderPass.endPass()
}
device.queue.submit([commandEncoder.finish()]);
为了完成三维物体的阴影渲染,在阴影映射有关的技术中一般会把阴影信息使用一个通道先绘制出来,然后把阴影信息传给下一个通道进而完成阴影的效果。
在上面的代码中,就使用了两个 RenderPassEncoder 进行阴影的先后步骤渲染。它们在 draw 之前就可以设置不同的渲染材料,包括代表行为的管线,以及代表资源的绑定组、各类缓冲等。
WebGPU 中的 Pipeline 被划分成了多个阶段,其中有三个阶段是可编程的,其它的阶段是可配置的。管线由于在三个可编程阶段拥有了着色器模块,所以管线对象更多的是扮演一个“执行者”,它代表的是某个单一计算过程的全部行为,而且是发生在 GPU 上。
而对于 PassEncoder,也就是通道编码器,它拥有一系列 setXXX 方法,它的角色更多的是“调度者”。
通道编码器在结束编码后,整个被编码的过程就代表了一个 Pass(通道)的计算流程。
多个时间很短的画面,就构成了动态的渲染结果。这每一个画面,叫做帧。而每一帧,在实时渲染技术中用多个“通道”,通过图形学或实时渲染知识有逻辑地组装在一起共同完成。
通道由行为和数据构成。
行为由着色器程序实现,也就是“你想在这一个通道做什么计算”,在 WebGL 中使用 WebGLProgram 附着两个着色器,而在 WebGPU 中使用 GPURenderPipeline/GPUComputePipeline 装配管线的各个阶段状态。
而数据,则希望读者去看我写的 Uniform 和 顶点缓冲文章了。
每一帧,在 WebGL 代码中,其实就是不断切换 WebGLProgram,绑定不同数据,最后发出 draw 动作完成;在 WebGPU 代码中,就是创建指令编码器、开始通道编码、结束通道编码、结束指令编码,最后提交指令缓冲完成。
WebGPU 把 WebGLProgram 与 WebGLShader 的行为职能抽离到 GPU[Render/Compute]Pipeline 和 GPUShaderModule 中去了,这样就可以在帧运算中独立出行为对象。
WebGL 使用 TypedArray 进行数据传递,这点 WebGPU 也是一样的。
下面的代码是 WebGL 1.0 常规的 VertexBuffer 创建、赋值、配置过程。
const positions = [
0, 0,
0, 0.5,
0.7, 0,
]
/*
创建着色器程序 program...
*/
// 获取 vertex attribute 在着色器中的位置
const positionAttributeLocation = gl.getAttribLocation(program, "a_position")
//#region 创建 WebGLBuffer 并绑定,随即写入数据
const positionBuffer = gl.createBuffer()
gl.bindBuffer(gl.ARRAY_BUFFER, positionBuffer)
gl.bufferData(gl.ARRAY_BUFFER, new Float32Array(positions), gl.STATIC_DRAW)
//#endregion
//#region 启用顶点着色器中对应的 attribute,再次绑定数据,并告知 WebGL 如何读取 VertexBuffer
gl.enableVertexAttribArray(positionAttributeLocation)
gl.bindBuffer(gl.ARRAY_BUFFER, positionBuffer)
gl.vertexAttribPointer(positionAttributeLocation, size, type, normalize, stride, offset)
//#endregion
WebGL 通过 gl 变量的 createBuffer、bindBuffer、bufferData 方法来创建缓冲、绑定当前要用什么缓冲及缓冲的用途、向缓冲传递 CPU 端的 TypedArray 数据并指明绘制模式,通过 gl 变量的 enableVertexAttribArray、vertexAttribPointer 方法来启用着色器中 attribute 的坑位、告诉着色器如何从 VertexBuffer 中获取顶点数据。
一个非常简单的顶点着色器:
precision mediump float;
attribute vec2 a_position;
void main() {
gl_Position = vec4(a_position, 0.0, 0.0);
}
如果用高版本的语法(譬如 WebGL 2.0 中用更高版本的 glsl 语法),你可以这样写:
#version 300 es
precision mediump float;
layout(location = 0) in vec2 a_position;
void main() {
gl_Position = vec4(a_position, 0.0, 0.0);
}
const verticesData = [
// 坐标 xy // 颜色 RGBA
-0.5, 0.0, 1.0, 0.0, 0.0, 1.0, // ← 顶点 1
0.0, 0.5, 0.0, 1.0, 0.0, 1.0, // ← 顶点 2
0.5, 0.0, 0.0, 0.0, 1.0, 1.0 // ← 顶点 3
])
const verticesBuffer = device.createBuffer({
size: vbodata.byteLength,
usage: GPUBufferUsage.VERTEX,
mappedAtCreation: true // 创建时立刻映射,让 CPU 端能读写数据
})
// 让 GPUBuffer 映射出一块 CPU 端的内存,即 ArrayBuffer,此时这个 Float32Array 仍是空的
const verticesBufferArray = new Float32Array(verticesBuffer.getMappedRange())
// 将数据传入这个 Float32Array
verticesBufferArray.set(verticesData)
// 令 GPUBuffer 解除映射,此时 verticesBufferArray 那块内存才能被 GPU 访问
verticesBuffer.unmap()
WebGPU 创建 VertexBuffer 是调取设备对象的 createBuffer 方法,返回一个 GPUBuffer 对象,它所需要的是指定 GPUBuffer 的类型以及缓冲的大小。如何写入这块缓冲呢?那还要提到“映射”这个概念。
映射简单的说就是让 CPU/GPU 单边访问。此处创建 GPUBuffer 的参数中有一个 mappedAtCreation 表示创建时就映射。
关于 WebGPU 中 Buffer 的映射、解映射,我有一篇专门的文章介绍,这里不展开过多了。
上面代码中 verticesBuffer.getMappedRange() 返回的是一个 ArrayBuffer,随后才进行 set 操作来填充数据。数据填充完毕后,还需要 unmap 来解映射,以供后续 GPU 能访问。
顶点着色阶段是 渲染管线(GPURenderPipeline) 的一个组成部分,管线需要知道顶点缓冲的数据规格,由着色器模块告知。
创建渲染管线需要 着色器模块对象(GPUShaderModule),顶点着色器模块的创建参数就有一个 buffers 属性,是一个数组,用于描述顶点着色器中访问到的顶点数据规格:
const vsShaderModule = device.createShaderModule({
// ...
buffers: [
{
// 2 个 float32 代表 xy 坐标
shaderLocation: 0,
offset: 0,
format: 'float32x2'
}, {
// 4 个 float32 代表 rgba 色值
shaderLocation: 1,
offset: 2 * verticesData.BYTES_PER_ELEMENT,
format: 'float32x4'
}
]
})
详细资料可查阅官方 API 文档中关于设备对象的 createShaderModule 方法的要求。
使用 渲染通道编码器(GPURenderPassEncoder) 来编码单个渲染通道的全流程,其中有一步要设置该通道的顶点缓冲。这个比较简单:
// ...
renderPassEncoder.setVertexBuffer(0, verticesBuffer)
// ...
struct PositionColorInput {
@location(0) in_position_2d: vec2<f32>;
@location(1) in_color_rgba: vec4<f32>;
};
struct PositionColorOutput {
@builtin(position) coords_output: vec4<f32>;
@location(0) color_output: vec4<f32>;
};
@stage(vertex)
fn main(input: PositionColorInput)
-> PositionColorOutput {
var output: PositionColorOutput;
output.color_output = input.in_color_rgba;
output.coords_output = vec4<f32>(input.in_position_2d, 0.0, 1.0);
return output;
}
WGSL 着色器代码可以自定义顶点着色器的入口函数名称、传入参数的结构,也可以自定义向下一阶段输出(即返回值)的结构。
可以看到,为了接收来自 WebGPU API 传递进来的顶点属性,即自定义结构中的 PositionColorInput 结构体中的 xy 坐标 in_position_2d,以及颜色值 in_color_rgba,需要有一个“特性”,叫做 location,它括号里的值与着色器模块对象中的 shaderLocation 必须对应上。
而对于输出,代码中则对应了结构体 PositionColorOutput,其中向下一阶段(即片段着色阶段)输出用到了内置特性(builtin),叫做 position,以及自定义的一个 vec4:color_output,它是片段着色器中光栅化后的颜色,这两个输出,类似 glsl 中的 varying(或者out)作用。
创建 GPUBuffer 的时候,如果没有 mappedAtCreation: true,那么内存、显存都没有被申请。
经过代码测试,当执行映射请求且成功映射后,内存就会占用掉对应的 GPUBuffer 的 size,此时完成了 ArrayBuffer 的创建,是要占空间的。
那么什么时候显存会被申请呢?猜测是 device.queue.commit() 时,指令缓冲携带着各种通道、各种 Buffer 一并传递给 GPU,执行指令缓冲,希望有高手测试我的猜测。
至于销毁,我使用 destory 方法测试 CPU 的内存情况,发现两分钟内并未回收,这一点待测试 ArrayBuffer 的回收情况。
gl.vertexAttribPointer() 方法的作用类似于 device.createShaderModule() 中 buffers 的作用,告诉着色器顶点缓冲单个顶点的数据规格。
gl.createBuffer() 和 device.createBuffer() 是类似的,都是创建一个 CPU 端内存中的 Buffer 对象,但实际并没有传入数据。
数据传递则不大一致了,WebGL 同一时刻只能指定一个 VertexBuffer,所以 gl.bindBuffer()、gl.bufferData() 一系列函数调用下来都沿着逻辑走;而 WebGPU 则需要经过映射和解映射。
在 WebGPU 中最重要的是,在 renderPassEncoder 记录发出 draw 指令之前,要调用 renderPassEncoder.setVertexBuffer() 方法显式指定用哪一个 VertexBuffer。
着色器代码请读者自行比对研究,只是语法上的差异。
VAO 我也写过一篇《WebGPU 中消失的 VAO》,这里就不详细展开了,有兴趣的读者请移步我的博客列表找找。
WebGPU 中已经不需要 VAO 了,源于 WebGPU 的机制与 WebGL 不同,VAO 本身是 OpenGL 体系提出的概念,它能节约 WebGL 切换顶点相关状态时的负担,也就是帮你缓存下来一个 VBO 的设定状态,而无需再 gl.bindBuffer()、gl.bufferData()、gl.vertexAttribPointer() 等再来一遍。
WebGPU 的装配式思想天然就与 VAO 是一致的。VAO 的职能转交给 GPURenderPipeline 完成,其创建参数 GPURenderPipelineDescriptor.vertex.buffers 属性是 GPUVertexBufferLayout[] 类型的,这每一个 GPUVertexBufferLayout 对象就有一部分 VAO 的职能。
OpenGL 体系给图形开发留下了不少的技术积累,其中就有不少的“Buffer”,耳熟能详的就有顶点缓冲对象(VertexbufferObject,VBO),帧缓冲对象(FramebufferObject,FBO)等。
切换到以三大现代图形开发技术体系为基础的 WebGPU 之后,这些经典的缓冲对象就在 API 中“消失了”。其实,它们的职能被更科学地分散到新的 API 去了。
本篇讲一讲 FBO 与 RBO,这两个通常用于离屏渲染逻辑中,以及到了 WebGPU 后为什么没有这两个 API 了(用什么作为了替代)。
WebGL 其实更多的角色是一个绘图 API,所以在 gl.drawArrays 函数发出时,必须确定将数据资源画到哪里去。
WebGL 允许 drawArrays 到两个地方中的任意一个:canvas 或 FramebufferObject. 很多资料都有介绍,canvas 有一个默认的帧缓冲,若不显式指定自己创建的帧缓冲对象(或者指定为 null)那就默认绘制到 canvas 的帧缓冲上。
换句话说,只要使用 gl.bindFramebuffer() 函数指定一个自己创建的帧缓冲对象,那么就不会绘制到 canvas 上。
本篇讨论的是 HTMLCanvasElement,不涉及 OffscreenCanvas
FBO 创建起来简单,它大多数时候就是一个负责点名的头儿,出汗水的都是小弟,也即它下辖的两类附件:
关于 MRT 技术(MultiRenderTarget),也就是允许输出到多个颜色附件的技术,WebGL 1.0 使用
gl.getExtension('WEBGL_draw_buffers')获取扩展来使用;而 WebGL 2.0 原生就支持,所以颜色附件的数量上有所区别。
而这两大类附件则通过如下 API 进行设置:
// 设置 texture 为 0 号颜色附件
gl.framebufferTexture2D(gl.FRAMEBUFFER, gl.COLOR_ATTACHMENT0, gl.TEXTURE_2D, color0Texture, 0)
// 设置 rbo 为 0 号颜色附件
gl.framebufferRenderbuffer(gl.FRAMEBUFFER, gl.COLOR_ATTACHMENT0, gl.RENDERBUFFER, color0Rbo)
// 设置 texture 为 仅深度附件
gl.framebufferTexture2D(gl.FRAMEBUFFER, gl.DEPTH_ATTACHMENT, gl.TEXTURE_2D, depthTexture, 0)
// 设置 rbo 为 深度模板附件(需要 WebGL2 或 WEBGL_depth_texture)
gl.framebufferRenderbuffer(gl.FRAMEBUFFER, gl.DEPTH_STENCIL_ATTACHMENT, gl.RENDERBUFFER, depthStencilRbo)
实际上,在需要进行 MRT 时,gl.COLOR_ATTACHMENT0、gl.COLOR_ATTACHMENT1 ... 这些属性只是一个数字,可以通过计算属性进行颜色附件的位置索引,也可以直接使用明确的数字代替:
console.log(gl.COLOR_ATTACHMENT0) // 36064
console.log(gl.COLOR_ATTACHMENT1) // 36065
let i = 1
console.log(gl[`COLOR_ATTACHMENT${i}`]) // 36065
颜色附件与深度模板附件是需要明确指定数据载体的。WebGL 若改将绘图结果绘制到非 canvas 的 FBO,那么就需要明确指定具体画在哪。
如 1.1 小节的示例代码所示,每个附件都可以选择如下二者之一作为真正的数据载体容器:
WebGLRenderbuffer)WebGLTexture)有前辈在博客中指出,渲染缓冲对象会比纹理对象稍好,但是要具体问题具体分析。
实际上,在大多数现代 GPU 以及显卡驱动程序上,这些性能差异没那么重要。
简单的说,如果离屏绘制的结果不需要再进行下一个绘制中作为纹理贴图使用,用 RBO 就可以,因为只有纹理对象能向着色器传递。
关于 RBO 和纹理作为两类附件的区别的资料就没那么多了,而且这篇主要是比对 WebGL 和 WebGPU 二者的不同,就不再展开了。
gl.framebufferTexture2D(gl.FRAMEBUFFER, <attachment_type>, <texture_type>, <texture>, <mip_level>):将 WebGLTexture 关联到 FBO 的某个附件上gl.framebufferRenderbuffer(gl.FRAMEBUFFER, <attachment_type>, gl.RENDERBUFFER, <rbo>):将 RBO 关联到 FBO 的某个附件上gl.bindFramebuffer(gl.FRAMEBUFFER, <fbo | null>):设置帧缓冲对象为当前渲染目标gl.bindRenderbuffer(gl.RENDERBUFFER, <rbo>):绑定 <rbo> 为当前的 RBOgl.renderbufferStorage(gl.RENDERBUFFER, <rbo_format>, width, height):设置当前绑定的 RBO 的数据格式以及长宽下面是三个创建的方法:
gl.createFramebuffer()gl.createRenderbuffer()gl.createTexture()顺带回顾一下纹理的参数设置、纹理绑定与数据传递函数:
gl.texParameteri():设置当前绑定的纹理对象的参数gl.bindTexture():绑定纹理对象为当前作用纹理gl.texImage2D():向当前绑定的纹理对象传递数据,最后一个参数即数据WebGPU 已经没有 WebGLFramebuffer 和 WebGLRenderbuffer 这种类似的 API 了,也就是说,你找不到 WebGPUFramebuffer 和 WebGPURenderbuffer 这俩类。
但是,gl.drawArray 的对等操作还是有的,那就是渲染通道编码器(令其为 renderPassEncoder)发出的 renderPassEncoder.draw 动作。
WebGPU 的绘制目标在哪呢?由于 WebGPU 与 canvas 元素不是强关联的,所以必须显式指定绘制到哪里去。
通过学习可编程通道以及指令编码等概念,了解到 WebGPU 是通过一些指令缓冲来向 GPU 传递“我将要干啥”的信息的,而指令缓冲(Command Buffer)则由指令编码器(也即 GPUCommandEncoder)完成创建。指令缓冲由若干个 Pass(通道)构成,绘制相关的通道,叫做渲染通道。
渲染通道则是由渲染通道编码器来设置的,一个渲染通道就设定了这个通道的绘制结果要置于何处(这个描述就类比了 WebGL 要绘制到哪儿)。具体到代码中,其实就是创建 renderPassEncoder 时,传递的 GPURenderPassDescriptor 参数对象里的 colorAttachments 属性:
const renderPassEncoder = commandEncoder.beginRenderPass({
// 是一个数组,可以设置多个颜色附件
colorAttachments: [
{
view: textureView,
loadValue: { r: 0.0, g: 0.0, b: 0.0, a: 1.0 },
storeOp: 'store',
}
]
})
注意到,colorAttachments[0].view 是一个 textureView,也即 GPUTextureView,换言之,意味着这个渲染通道要绘制到某个纹理对象上。
通常情况下,如果你不需要离屏绘制或者使用 msaa,那么应该是画到 canvas 上的,从 canvas 中获取其配置好的纹理对象如下操作:
const context = canvas.getContext('webgpu')
context.configure({
gpuDevice,
format: presentationFormat, // 此参数可以使用画布的客户端长宽 × 设备像素缩放比例得到,是一个两个元素的数组
size: presentationSize, // 此参数可以调用 context.getPreferredFormat(gpuAdapter) 获取
})
const textureView = context.getCurrentTexture().createView()
上述代码片段完成了渲染通道与屏幕 canvas 的关联,即把 canvas 视作一块 GPUTexture,使用其 GPUTextureView 与渲染通道的关联。
其实,更严谨的说法是 渲染通道 承担了 FBO 的部分职能(因为渲染通道还有发出其它动作的职能,例如设置管线等),因为没有 GPURenderPass 这个 API,所以只能委屈 GPURenderPassEncoder 代替一下了。
为了进行多目标渲染,也即片元着色器要输出多个结果的情况(代码中表现为返回一个结构体),就意味着要多个颜色附件来承载渲染的输出。
此时,要配置渲染管线的片元着色阶段(fragment)的 targets 属性。
相关的从创建纹理、创建管线、指令编码例子代码如下所示,用到两个纹理对象来充当颜色附件的容器:
// 一、创建渲染目标纹理 1 和 2,以及其对应的纹理视图对象
const renderTargetTexture1 = device.createTexture({
size: [/* 略 */],
usage: GPUTextureUsage.RENDER_ATTACHMENT | GPUTextureUsage.TEXTURE_BINDING,
format: 'rgba32float',
})
const renderTargetTexture2 = device.createTexture({
size: [/* 略 */],
usage: GPUTextureUsage.RENDER_ATTACHMENT | GPUTextureUsage.TEXTURE_BINDING,
format: 'bgra8unorm',
})
const renderTargetTextureView1 = renderTargetTexture1.createView()
const renderTargetTextureView2 = renderTargetTexture2.createView()
// 二,创建管线,配置片元着色阶段的多个对应目标的纹素输出格式
const pipeline = device.createRenderPipeline({
fragment: {
targets: [
{
format: 'rgba32float'
},
{
format: 'bgra8unorm'
}
]
// ... 其它属性省略
},
// ... 其它阶段省略
})
const renderPassEncoder = commandEncoder.beginRenderPass({
colorAttachments: [
{
view: renderTargetTextureView1,
// ... 其它参数
},
{
view: renderTargetTextureView2,
// ... 其它参数
}
]
})
这样,两个颜色附件分别用上了两个纹理视图对象作为渲染目标,而且在管线对象的片元着色阶段也明确指定了两个 target 的格式。
于是,你可以在片元着色器代码中指定输出结构:
struct FragmentStageOutput {
@location(0) something: vec4<f32>;
@location(1) another: vec4<f32>;
}
@stage(fragment)
fn main(/* 省略输入 */) -> FragmentStageOutput {
var output: FragmentStageOutput;
// 随便写俩数字,没什么意义
output.something = vec4<f32>(0.156);
output.another = vec4<f32>(0.67);
return output;
}
这样,位于 location 0 的 something 这个 f32 型四维向量就写入了 renderTargetTexture1 的一个纹素,而位于 location 1 的 another 这个 f32 型四维向量则写入了 renderTargetTexture2 的一个纹素。
尽管,在 pipeline 的片元阶段中 target 指定的 format 略有不一样,即 renderTargetTexture2 指定为 'bgra8unorm',而着色器代码中结构体的 1 号 location 数据类型是 vec4<f32>,WebGPU 会帮你把 f32 这个 [0.0f, 1.0f] 范围内的输出映射到 [0, 255] 这个 8bit 整数区间上的。
事实上,如果没有多输出(也即多目标渲染),WebGPU 中大部分片元着色器的返回类型就是一个单一的
vec4<f32>,而最常见的 canvas 最佳纹理格式是bgra8unorm,总归要发生[0.0f, 1.0f]通过放大 255 倍再取整到[0, 255]这个映射过程的。
GPURenderPassDescriptor 还支持传入 depthStencilAttachment,作为深度模板附件,代码举例如下:
const renderPassDescriptor = {
// 颜色附件设置略
depthStencilAttachment: {
view: depthTexture.createView(),
depthLoadValue: 1.0,
depthStoreOp: 'store',
stencilLoadValue: 0,
stencilStoreOp: 'store',
}
}
与单个颜色附件类似,也需要一个纹理对象的视图对象为 view,需要特别注意的是,作为深度或模板附件,一定要设置与深度、模板有关的纹理格式。
若对深度、模板的纹理格式在额外的设备功能(Device feature)中,在请求设备对象时一定要加上对应的 feature 来请求,例如有 "depth24unorm-stencil8" 这个功能才能用 "depth24unorm-stencil8" 这种纹理格式。
深度模板的计算,还需要注意渲染管线中深度模板阶段参数对象的配置,例如:
const renderPipeline = device.createRenderPipeline({
// ...
depthStencil: {
depthWriteEnabled: true,
depthCompare: 'less',
format: 'depth24plus',
}
})
除了深度模板附件里提及的纹理格式、请求设备的 feature 之外,还需要注意非 canvas 的纹理若作为某种附件,那它的 usage 一定包含 RENDER_ATTACHMENT 这一项。
const depthTexture = device.createTexture({
size: presentationSize,
format: 'depth24plus',
usage: GPUTextureUsage.RENDER_ATTACHMENT,
})
const renderColorTexture = device.createTexture({
size: presentationSize,
format: presentationFormat,
usage: GPUTextureUsage.RENDER_ATTACHMENT | GPUTextureUsage.COPY_SRC,
})
从 FBO 读像素值,实际上就是读颜色附件的颜色数据到 TypedArray 中,想读取当前 fbo(或 canvas 的帧缓冲)的结果,只需调用 gl.readPixels 方法即可。
//#region 创建 fbo 并将其设为渲染目标容器
const fb = gl.createFramebuffer();
gl.bindFramebuffer(gl.FRAMEBUFFER, fb);
//#endregion
//#region 创建离屏绘制的容器:纹理对象,并绑定它成为当前要处理的纹理对象
const texture = gl.createTexture();
gl.bindTexture(gl.TEXTURE_2D, texture);
// -- 若不需要作为纹理再次被着色器采样,其实这里可以用 RBO 代替
//#endregion
//#region 绑定纹理对象到 0 号颜色附件
gl.framebufferTexture2D(gl.FRAMEBUFFER, gl.COLOR_ATTACHMENT0, gl.TEXTURE_2D, texture, 0);
//#endregion
// ... gl.drawArrays 进行渲染
//#region 读取到 TypedArray
const pixels = new Uint8Array(imageWidth * imageHeight * 4);
gl.readPixels(0, 0, imageWiebdth, imageHeight, gl.RGBA, gl.UNSIGNED_BYTE, pixels);
//#endregion
gl.readPixels() 方法是把当前绑定的 FBO 及当前绑定的颜色附件的像素值读取到 TypedArray 中,无论载体是 WebGLRenderbuffer 还是 WebGLTexture.
唯一需要注意的是,如果你在写引擎,那么读像素的操作得在绘制指令(一般指 gl.drawArrays 或 gl.drawElements)发出后的代码中编写,否则可能会读不到值。
在 WebGPU 中将渲染目标,也即纹理中访问像素是比较简单的,使用到指令编码器的 copyTextureToBuffer 方法,将纹理对象的数据读取到 GPUBuffer,然后通过解映射、读范围的方式获取 ArrayBuffer.
//#region 创建颜色附件关联的纹理对象
const colorAttachment0Texture = device.createTexture({ /* ... */ })
//#endregion
//#region 创建用于保存纹理数据的缓冲对象
const readPixelsResultBuffer = device.createBuffer({
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ,
size: 4 * textureWidth * textureHeight,
})
//#endregion
//#region 图像拷贝操作,将 GPUTexture 拷贝到 GPUBuffer
const encoder = device.createCommandEncoder()
encoder.copyTextureToBuffer(
{ texture: colorAttachment0Texture },
{ buffer: readPixelsResultBuffer },
[textureWidth, textureHeight],
)
device.queue.submit([encoder.finish()])
//#endregion
//#region 读像素
await readPixelsResultBuffer.mapAsync()
const pixels = new Uint8Array(readPixelsResultBuffer.getMappedRange())
//#endregion
要额外注意,如果要拷贝到 GPUBuffer 并且要交给 CPU 端(也就是 JavaScript)来读取,那这块 GPUBuffer 的 usage 一定要有 COPY_DST 和 MAP_READ 这两项;而且,这个纹理对象的 usage 也必须要有 COPY_SRC 这一项(作为颜色附件的关联纹理,它还得有 RENDER_ATTACHMENT 这一个 usage)。
从 WebGL(也即 OpenGL ES 体系)到 WebGPU,离屏绘制技术、多目标渲染技术都有了接口和用法上的升级。
首先是取消了 RBO 这个概念,一律使用 Texture 作为绘制目标。
其次,更替了 FBO 的职权至 RenderPass,由 GPURenderPassEncoder 负责承载原来 FBO 的两类附件。
因为取消了 RBO 概念,所以 RTT(RenderToTexture) 和 RTR(RenderToRenderbuffer) 就不再存在了,但是离屏绘制技术依旧是存在的,你在 WebGPU 中可以使用多个 RenderPass 完成多个绘制成果,Texture 作为绘制载体可以自由地经过资源绑定组穿梭在不同的 RenderPass 的某个 RenderPipeline 中。
关于如何从 GPU 的纹理中读取像素(颜色值),第 3 节也有粗浅的讨论,这部分大多数用途是 GPU Picking;而关于 FBO 这个遗留概念,现在即 RenderPass 离屏渲染,最常见的还是做效果。
就不给定义了,直接简单的说,映射(Mapping)后的某块显存,就能被 CPU 访问。
三大图形 API(D3D12、Vulkan、Metal)的 Buffer(指显存)映射后,CPU 就能访问它了,此时注意,GPU 仍然可以访问这块显存。这就会导致一个问题:IO冲突,这就需要程序考量这个问题了。
WebGPU 禁止了这个行为,改用传递“所有权”来表示映射后的状态,颇具 Rust 的哲学。每一个时刻,CPU 和 GPU 是单边访问显存的,也就避免了竞争和冲突。
当 JavaScript 请求映射显存时,所有权并不是马上就能移交给 CPU 的,GPU 这个时候可能手头上还有别的处理显存的操作。所以,GPUBuffer 的映射方法是一个异步方法:
const someBuffer = device.createBuffer({ /* ... */ })
await someBuffer.mapAsync(GPUMapMode.READ, 0, 4) // 从 0 开始,只映射 4 个字节
// 之后就可以使用 getMappedRange 方法获取其对应的 ArrayBuffer 进行缓冲操作
不过,解映射操作倒是一个同步操作,CPU 用完后就可以解映射:
somebuffer.unmap()
注意,mapAsync 方法将会直接在 WebGPU 内部往设备的默认队列中压入一个操作,此方法作用于 WebGPU 中三大时间轴中的 队列时间轴。而且在 mapAsync 成功后,内存才会增加(实测)。
当向队列提交指令缓冲后(此指令缓冲的某个渲染通道要用到这块 GPUBuffer),内存上的数据才会提交给 GPU(猜测)。
由于测试地不多,我在调用 destroy 方法后并未显著看到内存的变少,希望有朋友能测试。
可以在创建缓冲时传递 mappedAtCreation: true,这样甚至都不需要声明其 usage 带有 GPUBufferUsage.MAP_WRITE
const buffer = device.createBuffer({
usage: GPUBufferUsage.UNIFORM,
size: 256,
mappedAtCreation: true,
})
// 然后马上就可以获取映射后的 ArrayBuffer
const mappedArrayBuffer = buffer.getMappedRange()
/* 在这里执行一些写入操作 */
// 解映射,还管理权给 GPU
buffer.unmap()
JavaScript 这端会在 rAF 中频繁地将大量数据传递给 GPUBuffer 映射出来的 ArrayBuffer,然后随着解映射、提交指令缓冲到队列,最后传递给 GPU.
上述最常见的例子莫过于传递每一帧所需的 VertexBuffer、UniformBuffer 以及计算通道所需的 StorageBuffer 等。
使用队列对象的 writeBuffer 方法写入缓冲对象是非常高效率的,但是与用来写入的映射后的一个 GPUBuffer 相比,writeBuffer 有一个额外的拷贝操作。推测会影响性能,虽然官方推荐的例子中有很多 writeBuffer 的操作,大多数是用于 UniformBuffer 的更新。
这样反向的传递比较少,但也不是没有。譬如屏幕截图(保存颜色附件到 ArrayBuffer)、计算通道的结果统计等,就需要从 GPU 的计算结果中获取数据。
譬如,官方给的从渲染的纹理中获取像素数据例子:
const texture = getTheRenderedTexture()
const readbackBuffer = device.createBuffer({
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ,
size: 4 * textureWidth * textureHeight,
})
// 使用指令编码器将纹理拷贝到 GPUBuffer
const encoder = device.createCommandEncoder()
encoder.copyTextureToBuffer(
{ texture },
{ buffer, rowPitch: textureWidth * 4 },
[textureWidth, textureHeight],
)
device.submit([encoder.finish()])
// 映射,令 CPU 端的内存可以访问到数据
await buffer.mapAsync(GPUMapMode.READ)
// 保存屏幕截图
saveScreenshot(buffer.getMappedRange())
// 解映射
buffer.unmap()
WebGPU 的几个最佳实践
来自 2022 WebGL & WebGPU Meetup 的 幻灯片
WebGPU 中的每个对象都有 label 属性,不管你是创建它的时候通过传递 descriptor 的 label 属性也好,亦或者是创建完成后直接访问其 label 属性也好。这个属性类似于一个 id,它能让对象更便于调试和观察,写它几乎不需要什么成本考量,但是调试的时候会非常、非常爽。
const projectionMatrixBuffer = gpuDevice.createBuffer({
label: 'Projection Matrix Buffer',
size: 12 * Float32Array.BYTES_PER_ELEMENT, // 故意设的 12,实际上矩阵应该要 16
usage: GPUBufferUsage.VERTEX | GPUBufferUsage.COPY_DST,
})
const projectionMatrixArray = new Float32Array(16)
gpuDevice.queue.writeBuffer(projectionMatrixBuffer, 0, projectionMatrixArray)
上面代码故意写错的矩阵所用 GPUBuffer 的大小,在错误校验的时候就会带上 label 信息了:
// 控制台输出
Write range (bufferOffset: 0, size: 64) does not fit in [Buffer "Projection Matrix Buffer"] size (48).
指令缓冲(CommandBuffer)允许你增删调试组,调试组其实就是一组字符串,它指示的是哪部分代码在执行。错误校验的时候,报错消息会显示调用堆栈:
// --- 第一个调试点:标记当前帧 ---
commandEncoder.pushDebugGroup('Frame ${frameIndex}');
// --- 第一个子调试点:标记灯光的更新 ---
commandEncoder.pushDebugGroup('Clustered Light Compute Pass');
// 譬如,在这里更新光源
updateClusteredLights(commandEncoder);
commandEncoder.popDebugGroup();
// --- 结束第一个子调试点 ---
// --- 第二个子调试点:标记渲染通道开始 ---
commandEncoder.pushDebugGroup('Main Render Pass');
// 触发绘制
renderScene(commandEncoder);
commandEncoder.popDebugGroup();
// --- 结束第二个子调试点
commandEncoder.popDebugGroup();
// --- 结束第一个调试点 ---
这样,如果有报错消息,就会提示:
// 控制台输出
Binding sizes are too small for bind group [BindGroup] at index 0
Debug group stack:
> "Main Render Pass"
> "Frame 234"
使用 Blob 创建的 ImageBitmaps 可以获得最佳的 JPG/PNG 纹理解码性能。
/**
* 根据纹理图片路径异步创建纹理对象,并将纹理数据拷贝至对象中
* @param {GPUDevice} gpuDevice 设备对象
* @param {string} url 纹理图片路径
*/
async function createTextureFromImageUrl(gpuDevice, url) {
const blob = await fetch(url).then((r) => r.blob())
const source = await createImageBitmap(blob)
const textureDescriptor = {
label: `Image Texture ${url}`,
size: {
width: source.width,
height: source.height,
},
format: 'rgba8unorm',
usage: GPUTextureUsage.TEXTURE_BINDING | GPUTextureUsage.COPY_DST
}
const texture = gpuDevice.createTexture(textureDescriptor)
gpuDevice.queue.copyExternalImageToTexture(
{ source },
{ texture },
textureDescriptor.size,
)
return texture
}
能用就用。
WebGPU 支持至少 3 种压缩纹理类型:
支持多少是取决于硬件能力的,根据官方的讨论(Github Issue 2083),全平台都要支持 BC 格式(又名 DXT、S3TC),或者 ETC2、ASTC 压缩格式,以保证你可以用纹理压缩能力。
强烈推荐使用超压缩纹理格式(例如 Basis Universal),好处是可以无视设备,它都能转换到设备支持的格式上,这样就避免准备两种格式的纹理了。
原作者写了个库,用于在 WebGL 和 WebGPU 种加载压缩纹理,参考 Github toji/web-texture-tool
WebGL 诞生之初对压缩纹理的支持不太好,以致于后来用 extension 的方式加载压缩纹理让开发者有点不好受。现在 WebGPU 原生就支持,所以 WebGPU 在这方面还是考虑了历史经验的。
这是一个开源库,你可以在 GitHub 上找到它,它提供了命令行工具。
譬如,你可以使用它来压缩 glb 种的纹理:
> gltf-transform etc1s paddle.glb paddle2.glb
paddle.glb (11.92 MB) → paddle2.glb (1.73 MB)
做到了视觉无损,但是从 Blender 导出的这个模型的体积能小很多。原模型的纹理是 5 张 2048 x 2048 的 PNG 图。
这库除了压缩纹理,还能缩放纹理,重采样,给几何数据附加 Google Draco 压缩等诸多功能。最终优化下来,glb 的体积只是原来的 5% 不到。
> gltf-transform resize paddle.glb paddle2.glb --width 1024 --height 1024
> gltf-transform etc1s paddle2.glb paddle2.glb
> gltf-transform resample paddle2.glb paddle2.glb
> gltf-transform dedup paddle2.glb paddle2.glb
> gltf-transform draco paddle2.glb paddle2.glb
paddle.glb (11.92 MB) → paddle2.glb (596.46 KB)
WebGPU 中有很多种方式将数据传入缓冲,writeBuffer() 方法不一定是错误用法。当你在 wasm 中调用 WebGPU 时,你应该优先考虑 writeBuffer() 这个 API,这样就避免了额外的缓冲复制操作。
const projectionMatrixBuffer = gpuDevice.createBuffer({
label: 'Projection Matrix Buffer',
size: 16 * Float32Array.BYTES_PER_ELEMENT,
usage: GPUBufferUsage.VERTEX | GPUBufferUsage.COPY_DST,
});
// 当投影矩阵改变时(例如 window 改变了大小)
function updateProjectionMatrixBuffer(projectionMatrix) {
const projectionMatrixArray = projectionMatrix.getAsFloat32Array();
gpuDevice.queue.writeBuffer(projectionMatrixBuffer, 0, projectionMatrixArray);
}
原作者指出,创建 buffer 时设 mappedAtCreation 并不是必须的,有时候创建时不映射也是可以的,譬如对 glTF 中有关的缓冲加载。
如果你不是马上就要渲染管线或者计算管线,尽量用 createRenderPipelineAsync 和 createComputePipelineAsync 这俩 API 来替代同步创建。
同步创建 pipeline,有可能会在底层去把管线的有关资源进行编译,这会中断 GPU 有关的步骤。
而对于异步创建,pipeline 没准备好就不会 resolve Promise,也就是说可以优先让 GPU 当前在干的事情先做完,再去折腾我所需要的管线。
下面看看对比代码:
// 同步创建计算管线
const computePipeline = gpuDevice.createComputePipeline({/* ... */})
computePass.setPipeline(computePipeline)
computePass.dispatch(32, 32) // 此时触发调度,着色器可能在编译,会卡
再看看异步创建的代码:
// 异步创建计算管线
const asyncComputePipeline = await gpuDevice.createComputePipelineAsync({/* ... */})
computePass.setPipeline(asyncComputePipeline)
computePass.dispatch(32, 32) // 这个时候着色器早已编译好,没有卡顿,棒棒哒
隐式管线布局,尤其是独立的计算管线,或许对写 js 的时候很爽,但是这么做会带来俩潜在问题:
如果你的情况特别简单,可以使用隐式管线布局,但是能用显式创建管线布局就显式创建。
下面就是所谓的隐式管线布局的创建方式,先创建的管线对象,而后调用管线的 getBindGroupLayout() API 推断着色器代码中所需的管线布局对象。
const computePipeline = await gpuDevice.createComputePipelineAsync({
// 不传递布局对象
compute: {
module: computeModule,
entryPoint: 'computeMain'
}
})
const computeBindGroup = gpuDevice.createBindGroup({
// 获取隐式管线布局对象
layout: computePipeline.getBindGroupLayout(0),
entries: [{
binding: 0,
resource: { buffer: storageBuffer },
}]
})
如果在渲染/计算过程中,有一些数值是不会变但是频繁要用的,这种情况你可以创建一个简单一点的资源绑定组布局,可用于任意一个使用了同一号绑定组的管线对象上。
首先,创建资源绑定组及其布局:
// 创建一个相机 UBO 的资源绑定组布局及其绑定组本体
const cameraBindGroupLayout = device.createBindGroupLayout({
label: `Camera uniforms BindGroupLayout`,
entries: [{
binding: 0,
visibility: GPUShaderStage.VERTEX | GPUShaderStage.FRAGMENT,
buffer: {},
}]
})
const cameraBindGroup = gpu.device.createBindGroup({
label: `Camera uniforms BindGroup`,
layout: cameraBindGroupLayout,
entries: [{
binding: 0,
resource: { buffer: cameraUniformsBuffer, },
}],
})
随后,创建两条渲染管线,注意到这两条管线都用到了两个资源绑定组,有区别的地方就是用的材质资源绑定组是不一样的,共用了相机资源绑定组:
const renderPipelineA = gpuDevice.createRenderPipeline({
label: `Render Pipeline A`,
layout: gpuDevice.createPipelineLayout([cameraBindGroupLayout, materialBindGroupLayoutA]),
/* Etc... */
});
const renderPipelineB = gpuDevice.createRenderPipeline({
label: `Render Pipeline B`,
layout: gpuDevice.createPipelineLayout([cameraBindGroupLayout, materialBindGroupLayoutB]),
/* Etc... */
});
最后,在渲染循环的每一帧中,你只需设置一次相机的资源绑定组,以减少 CPU ~ GPU 的数据传递:
const renderPass = commandEncoder.beginRenderPass({/* ... */});
// 只设定一次相机的资源绑定组
renderPass.setBindGroup(0, cameraBindGroup);
for (const pipeline of activePipelines) {
renderPass.setPipeline(pipeline.gpuRenderPipeline)
for (const material of pipeline.materials) {
// 而对于管线中的材质资源绑定组,就分别设置了
renderPass.setBindGroup(1, material.gpuBindGroup)
// 此处设置 VBO 并发出绘制指令,略
for (const mesh of material.meshes) {
renderPass.setVertexBuffer(0, mesh.gpuVertexBuffer)
renderPass.draw(mesh.drawCount)
}
}
}
renderPass.endPass()
参考:
https://www.khronos.org/opengl/wiki/Tutorial2:_VAOs,VBOs,Vertex_and_Fragment_Shaders(C/_SDL)
其中有一段文字记录了 VAO 是什么:
A Vertex Array Object (VAO) is an object which contains one or more Vertex Buffer Objects and is designed to store the information for a complete rendered object. In our example this is a diamond consisting of four vertices as well as a color for each vertex.
VAO 记录的是多个(一组) VBO 的 gl.bindBuffer 和 gl.vertexAttribPointer (WebGL API)的状态,省去切换另一组 VBO 时再次设置绑定关系和读取规则的成本。
里面也描述了 VBO 是什么:一个 VBO 可以是 position,也可以是 uv,甚至可以是 indices;当然,在 WebGL 中,你可以用 1 个 VBO 来存储 position + uv + normal,但是不能和 indices 混用(和 type 有关)。
WebGPU 不需要 VAO 了,源于 WebGPU 的机制,并不是过程式,所以不需要借助 VAO 保存绑定一组 VBO 并读取它的状态。
当 device.createShaderModule 时,就有 buffers 属性描述着色器需要什么类型的数据,类似 gl.vertexAttribPointer 的作用;
而 gl.bindBuffer 的操作则由 renderPass.setVertexBuffer 完成;
关于数据的传递,gl.bufferData 的任务就由 device.createBuffer 时通过映射、解映射的机制将 TypedArray 传递进 GPUBuffer 来替代
那么谁能在渲染时告诉着色器,我有多组 VBO 要切换呢?
准确的说,VBO 这个概念已经被 GPUBuffer + GPUShaderModule 替代了,由后者两个对象共同分担,GPUBuffer 专注于 cpu~gpu 的数据传递,GPUShaderModule 不仅仅是着色器代码本身,还承担着 GPUBuffer[type=vertex] 的数据如何读取的职能(替代了 gl.vertexAttribPointer 的职能)。
VAO 的职能则转至 GPURenderPipeline 完成,其 GPURenderPipelineDescriptor.GPUVertexState.buffers 属性是 GPUVertexBufferLayout[] 类型的,这每一个 GPUVertexBufferLayout 对象就类似于 VAO 的职能。
下列只有一个 GPUVertexBufferLayout:
const renderPipeline = device.createRenderPipeline({
/* ... */
vertex: {
module: device.createShaderModule({
code: ` /* wgsl vertex shader code */ `,
}),
entryPoint: 'vertex_main',
buffers: [
{
arrayStride: 4 * 5, // 一个顶点数据占 20 bytes
attributes: [
{
// for Position VertexAttribute
shaderLocation: 0,
offset: 0,
format: "float32x3" // 其中顶点的坐标属性占 12 字节,三个 float32 数字
},
{
// for UV0 VertexAttribute
shaderLocation: 1,
offset: 3 * 4,
format: "float32x2" // 顶点的纹理坐标占 8 字节,两个 float32 数字
}
]
}
]
}
})
下面有两个 GPUVertexBufferLayout:
const renderPipeline = device.createRenderPipeline({
vertex: {
module: spriteShaderModule,
entryPoint: 'vert_main',
buffers: [
{
arrayStride: 4 * 4,
stepMode: 'instance',
attributes: [
{
// instance position
shaderLocation: 0,
offset: 0,
format: 'float32x2',
},
{
// instance velocity
shaderLocation: 1,
offset: 2 * 4,
format: 'float32x2',
},
],
},
{
arrayStride: 2 * 4,
stepMode: 'vertex',
attributes: [
{
// vertex positions
shaderLocation: 2,
offset: 0,
format: 'float32x2',
},
],
},
],
},
/* ... */
});
通过 renderPassEncoder.setVertexBuffer 就能切换 VBO 了:
renderPassEncoder.setVertexBuffer(0, bf0);
renderPassEncoder.setVertexBuffer(1, bf1);
WebGL 获取的是 WebGLRenderingContext/WebGLRenderingContext2 对象,必须依赖于有合适宽度和高度的 HTMLCanvasElement,通常命名为 gl,gl 变量有非常多方法,允许修改 WebGL 的全局状态
const gl = document.getElementById("id")?.getContext("webgl")
// ...
而 WebGPU 则不依赖具体的 Canvas,它操作的是物理图形卡设备,并使用 ES6/7 的异步语法获取,获取的是 GPUAdapter 和 GPUDevice,但是与 WebGLRenderingContext 起着类似“发出大多数命令”的大管家式角色的,更多是 GPUDevice 对象
const entryFn = async () => {
if (!navigator.gpu) {
return
}
// 测试版 Chrome 有可能返回 null
const adapter = await navigator.gpu.requestAdapter()
if (!adapter) {
return
}
const device = await adapter.requestDevice()
// ...
}
entryFn()
WebGPU 的入口是 navigator.gpu 对象,这个对象在 WebWorker 中也有,所以对 CPU 端的多线程有良好的支持。使用此对象异步请求适配器后,再使用适配器请求具象化的设备对象即可。
至于“适配器”和“设备”的概念界定,需要读者自行阅读 WebGPU Explainer、WebGPU Specification Core Object 等资料,前者大概是物理设备的一个变量符号,而根据不同的场景、线程需求再次请求“设备”,此设备并非物理设备,只是一个满足代码上下文所需要条件的、更实际的“对象”。
每次请求的适配器对象是不同的,不具备单例特征。
设备对象用于创建 WebGPU 中几乎所有的子类型,包括 GPUBuffer、GPUTexture 等,以及访问一些自有属性,例如队列属性 device.queue.
在 WebGLRenderingContext 时,允许传递一些参数:
const gl = canvasEle.getContext("webgl", {
alpha: false, // 是否包含透明度缓存区
antialias: false, // 是否开抗锯齿
depth: false, // 是否包含一个16位的深度缓冲区
stencil: false, // 是否包含一个8位的模板缓冲区
failIfMajorPerformanceCaveat: false, // 在系统性能低的环境中是否创建上下文
powerPreference: "high-performance", // GPU电源配置,"high-performance" 是高性能
preserveDrawingBuffer: false, // 是否保留缓冲区
premultipliedAlpha: false, // 是否预乘透明度通道
})
在请求 WebGPU 的适配器时,保留了性能选项(当前规范)powerPreference:
// in async function
const adapter = await navigator.gpu.requestAdapter({
powerPreference: "high-performance",
})
关于 requestAdapter 方法的参数,其类型 GPURequestAdapterOptions 定义,见下:
dictionary GPURequestAdapterOptions {
GPUPowerPreference powerPreference;
boolean forceFallbackAdapter = false;
};
enum GPUPowerPreference {
"low-power",
"high-performance",
};
forceFallbackAdapter 参数用得不多,有需要的读者可自行查询官方文档。
请求设备对象时,则允许传入 GPUDeviceDescriptor 参数对象,该对象允许有两个可选参数,一个是 requiredFeatures,类型为 string[],另一个是 requiredLimits,类型是键为 string 值为 number 的对象:
dictionary GPUDeviceDescriptor : GPUObjectDescriptorBase {
sequence<GPUFeatureName> requiredFeatures = [];
record<DOMString, GPUSize64> requiredLimits = {};
};
requireFeatures 数组的元素是字符串,不是随便填的,要参考 WebGPU Spec 24 功能索引表 中的功能。传递这个功能数组,就意味着要向适配器请求有这么多功能的设备对象;
requireLimits 则向图形处理器请求判断,我传递进来的这个要求,你能不能满足。
如果超过了适配器的 limits,那么请求将失败,适配器的 requestDevice 方法将返回一个 reject 的 Promise;
如果传入的限制条目的要求没有比全局默认值更好(有“更大更好”和“更小更好”,参考 WebGPU 第3章 中有关 limits 的表述),那就返回带默认值的设备对象,并 resolve Promise;
其中,限制条目有哪些,默认值是多少,对某个限制条目“更大值更好”还是“更小值更好”,要参考 WebGPU Spec 3.6 限制 中的表格。
上面这么说会比较抽象,下面举例说明。
例如下面这个例子,请求设备对象时,会问适配器能不能满足我要求的条件:
const device = await adapter.requestDevice({
maxBindGroups: 2,
maxUniformBuffersPerShaderStage: 4,
maxTextureDimension2D: 2048,
})
显然,请求的这三个条件都满足要求,返回的设备对象的限制列表都按所有限制条目的默认值来。
console.log(device.limits)
{
maxBindGroup: 4,
maxUniformBuffersPerShaderStage: 12,
maxTextureDimension2D: 8192,
// ...
}
关于这段,requiredLimits 的含义是“我的程序可能要这样的要求,你这个适配器能不能满足”,而不是“我要这么多要求,你给我返回一个这些参数的设备对象”。设备的创建过程,在 WebGPU Specification 的第 3 章,核心对象 - 设备中有详细描述。
WebGL 的请求参数包括了性能参数和功能参数,较为简单。
WebGPU 分成了两个阶段,请求适配器时可以对性能作要求,请求设备对象时可以对使用 GPU 时各个方面的参数作校验能不能满足程序要求。
这篇讲讲历史,不太适合直奔主题的朋友们。
你若往 Web 图形技术的底层去深究,一定能追溯到上个世纪 90 年代提出的 OpenGL 技术,也一定能看到,WebGL 就是基于 OpenGL ES 做出来的这些信息。OpenGL 在那个显卡羸弱的年代发挥了它应有的价值。
我们都知道现在的显卡都要安装显卡驱动程序,通过显卡驱动程序暴露的 API,我们就可以操作 GPU 完成图形处理器的操作。
问题就是,显卡驱动和普通编程界的汇编一样,底层,不好写,于是各大厂就做了封装 —— 码界的基操。
OpenGL 就是干这个的,负责上层接口封装并与下层显卡驱动打交道,但是,众所周知,它的设计风格已经跟不上现代 GPU 的特性了。
Microsoft 为此做出来最新的图形API 是 Direct3D 12,Apple 为此做出来最新的图形API 是 Metal,有一个著名的组织则做出来 Vulkan,这个组织名叫 Khronos。D3D12 现在在发光发热的地方是 Windows 和 PlayStation,Metal 则是 Mac 和 iPhone,Vulkan 你可能在安卓手机评测上见得多。这三个图形 API 被称作三大现代图形API,与现代显卡(无论是PC还是移动设备)的联系很密切。
噢,忘了一提,OpenGL 在 2006 年把丢给了 Khronos 管,现在各个操作系统基本都没怎么装这个很老的图形驱动了。
那问题来了,基于 OpenGL ES 的 WebGL 为什么能跑在各个操作系统的浏览器?
因为 WebGL 再往下已经可以不是 OpenGL ES 了,在 Windows 上现在是通过 D3D 转译到显卡驱动的,在 macOS 则是 Metal,只不过时间越接近现在,这种非亲儿子式的实现就越发困难。
苹果的 Safari 浏览器最近几年才珊珊支持 WebGL 2.0,而且已经放弃了 OpenGL ES 中 GPGPU 的特性了,或许看不到 WebGL 2.0 的 GPGPU 在 Safari 上实现了,果子哥现在正忙着 Metal 和更伟大的 M 系列自研芯片呢。
所以,综上所述,下一代的 Web 图形接口不叫 WebGL 3.0 的原因,你清楚了吗?已经不是 GL 一脉的了,为了使现代巨头在名称上不打架,所以采用了更贴近硬件名称的 WebGPU,WebGPU 从根源上和 WebGL 就不是一个时代的,无论是编码风格还是性能表现上。
题外话,OpenGL 并不是没有学习的价值,反而它还会存在一段时间,WebGL 也一样。
WebGL 实际上可以说是 OpenGL 的影子,OpenGL 的风格对 WebGL 的风格影响巨大。
学习过 WebGL 接口的朋友都知道一个东西:gl 变量,准确的说是 WebGLRenderingContext 对象,WebGL 2.0 则是 WebGLRenderingContext2.
无论是操作着色器,还是操作 VBO,亦或者是创建一些 Buffer、Texture 对象,基本上都得通过 gl 变量一条一条函数地走过程,顺序是非常讲究的,例如,下面是创建两大着色器并执行编译、连接的代码:
const vertexShaderCode = `
attribute vec4 a_position;
void main() {
gl_Position = a_position;
}
`
const fragmentShaderCode = `
precision mediump float;
void main() {
gl_FragColor = vec4(1, 0, 0.5, 1);
}
`
const vertexShader = gl.createShader(gl.VERTEX_SHADER)
gl.shaderSource(vertexShader, vertexShaderCode)
gl.compileShader(vertexShader)
const fragmentShader = gl.createShader(gl.FRAGMENT_SHADER)
gl.shaderSource(fragmentShader, fragmentShaderCode)
gl.compileShader(fragmentShader)
const program = gl.createProgram()
gl.attachShader(program, vertexShader)
gl.attachShader(program, fragmentShader)
gl.linkProgram(program)
// 还需要显式指定你需要用哪个 program
gl.useProgram(program)
// 继续操作顶点数据并触发绘制
// ...
创建着色器、赋予着色器代码并编译的三行 js WebGL 调用,可以说是必须这么写了,顶多 vs 和 fs 的创建编译顺序可以换一下,但是又必须在 program 之前完成这些操作。
有人说这无所谓,可以封装成 JavaScript 函数,隐藏这些过程细节,只需传递参数即可。是,这是一个不错的封装,很多 js 库都做过,并且都很实用。
但是,这仍然有难以逾越的鸿沟 —— 那就是 OpenGL 本身的问题。
每一次调用 gl.xxx 时,都会完成 CPU 到 GPU 的信号传递,改变 GPU 的状态,是立即生效的。熟悉计算机基础的朋友应该知道,计算机内部的时间和硬件之间的距离有多么重要,世人花了几十年时间无不为信号传递付出了努力,上述任意一条 gl 函数改变 GPU 状态的过程,大致要走完 CPU ~ 总线 ~ GPU 这么长一段距离。
我们都知道,办事肯定是一次性备齐材料的好,不要来来回回跑那么多遍,而 OpenGL 就是这样子的。有人说为什么要这样而不是改成一次发送的样子?历史原因,OpenGL 盛行那会儿 GPU 的工作没那么复杂,也就不需要那么超前的设计。
综上所述,WebGL 是存在 CPU 负载隐患的,是由于 OpenGL 这个状态机制决定的。
现代三大图形API 可不是这样,它们更倾向于先把东西准备好,最后提交给 GPU 的就是一个完整的设计图纸和缓冲数据,GPU 只需要拿着就可以专注办事。
WebGPU 虽然也有一个总管家一样的对象 —— device,类型是 GPUDevice,表示可以操作 GPU 设备的一个高层级抽象,它负责创建操作图形运算的各个对象,最后装配成一个叫 “CommandBuffer(指令缓冲,GPUCommandBuffer)”的对象并提交给队列,这才完成 CPU 这边的劳动。
所以,device.createXXX 创建过程中的对象时,并不会像 WebGL 一样立即通知 GPU 完成状态的改变,而是在 CPU 端写的代码就从逻辑、类型上确保了待会传递给 GPU 的东西是准确的,并让他们按自己的坑站好位,随时等待提交给 GPU。
在这里,指令缓冲对象具备了完整的数据资料(几何、纹理、着色器、管线调度逻辑等),GPU 一拿到就知道该干什么。
// 在异步函数中
const device = await adapter.requestDevice()
const buffer = device.createBuffer({
/* 装配几何,传递内存中的数据,最终成为 vertexAttribute 和 uniform 等资源 */
})
const texture = device.createTexture({
/* 装配纹理和采样信息 */
})
const pipelineLayout = device.createPipelineLayout({
/* 创建管线布局,传递绑定组布局对象 */
})
/* 创建着色器模块 */
const vertexShaderModule = device.createShaderModule({ /* ... */ })
const fragmentShaderModule = device.createShaderModule({ /* ... */ })
/*
计算着色器可能用到的着色器模块
const computeShaderModule = device.createShaderModule({ /* ... * / })
*/
const bindGroupLayout = device.createBindGroupLayout({
/* 创建绑定组的布局对象 */
})
const pipelineLayout = device.createPipelineLayout({
/* 传递绑定组布局对象 */
})
/*
上面两个布局对象其实可以偷懒不创建,绑定组虽然需要绑定组布局以
通知对应管线阶段绑定组的资源长啥样,但是绑定组布局是可以由
管线对象通过可编程阶段的代码自己推断出来绑定组布局对象的
本示例代码保存了完整的过程
*/
const pipeline = device.createRenderPipeline({
/*
创建管线
指定管线各个阶段所需的素材
其中有三个阶段可以传递着色器以实现可编程,即顶点、片段、计算
每个阶段还可以指定其所需要的数据、信息,例如 buffer 等
除此之外,管线还需要一个管线的布局对象,其内置的绑定组布局对象可以
让着色器知晓之后在通道中使用的绑定组资源是啥样子的
*/
})
const bindGroup_0 = deivce.createBindGroup({
/*
资源打组,将 buffer 和 texture 归到逻辑上的分组中,
方便各个过程调用,过程即管线,
此处必须传递绑定组布局对象,可以从管线中推断获取,也可以直接传递绑定组布局对象本身
*/
})
const commandEncoder = device.createCommandEncoder() // 创建指令缓冲编码器对象
const renderPassEncoder = commandEncoder.beginRenderPass() // 启动一个渲染通道编码器
// 也可以启动一个计算通道
// const computePassEncoder = commandEncoder.beginComputePass({ /* ... */ })
/*
以渲染通道为例,使用 renderPassEncoder 完成这个通道内要做什么的顺序设置,例如
*/
// 第一道绘制,设置管线0、绑定组0、绑定组1、vbo,并触发绘制
renderPassEncoder.setPipeline(renderPipeline_0)
renderPassEncoder.setBindGroup(0, bindGroup_0)
renderPassEncoder.setBindGroup(1, bindGroup_1)
renderPassEncoder.setVertexBuffer(0, vbo, 0, size)
renderPassEncoder.draw(vertexCount)
// 第二道绘制,设置管线1、另一个绑定组并触发绘制
renderPassEncoder.setPipeline(renderPipeline_1)
renderPassEncoder.setBindGroup(1, another_bindGroup)
renderPassEncoder.draw(vertexCount)
// 结束通道编码
renderPassEncoder.endPass()
// 最后提交至 queue,也即 commandEncoder 调用 finish 完成编码,返回一个指令缓冲
device.queue.submit([
commandEncoder.finish()
])
上述过程是 WebGPU 的一般化代码,很粗糙,没什么细节,不过基本上就是这么个逻辑。
对通道编码器的那部分代码,笔者保留的比较完整,让读者更好观察一个指令编码器是如何编码通道,并最后结束编码创建指令缓冲提交给队列的。
用做菜来比喻,OpenGL 系的编程就好比做一道菜时需要什么调料就去拿什么调料,做好一道菜再继续做下一道菜;而现代图形API 则是多灶台开火,所有材料都在合适的位置上,包括处理好的食材和辅料,即使一个厨师(CPU)都可以同时做好几道菜,效率很高。
WebGL 的总管家对象是 gl 变量,它必须依赖 HTML Canvas 元素,也就是说必须由主线程获取,也只能在主线程调度 GPU 状态,WebWorker 技术的多线程能力只能处理数据,比较鸡肋。
WebGPU 改变了总管家对象的获取方式,adapter 对象所依赖的 navigator.gpu 对象在 WebWorker 中也可以访问,所以在 Worker 中也可以创建 device,也可以装配出指令缓冲,从而实现多线程提交指令缓冲,实现 CPU 端多线程调度 GPU 的能力。
如果说 WebWorker 是 CPU 端的多线程,那么 GPU 本身的多线程也要用上。
能实现这一点的,是一个叫做“计算着色器”的东西,它是可编程管线中的一个可编程阶段,在 OpenGL 中可谓是姗姗来迟(因为早期的显卡并没挖掘其并行通用计算的能力),更别说 WebGL 到了 2.0 才支持了,苹果老兄甚至压根就懒得给 WebGL 2.0 实现这个特性。
WebGPU 出厂就带这玩意儿,通过计算着色器,使用 GPU 中 CU(Compute Unit,计算单元)旁边的共享内存,速度比普通的显存速度快得多。
有关计算着色器的资料不是特别多,目前只能看例子,在参考资料中也附带了一篇博客。
将 GPGPU 带入 Web 端后,脚本语言的运行时(deno、浏览器JavaScript,甚至未来的 nodejs 也有可能支持 WebGPU)就可以访问 GPU 的强大并行计算能力,据说 tensorflow.js 改用 WebGPU 作为后置技术后性能有极为显著的提升,对深度学习等领域有极大帮助,即使用户的浏览器没那么新潮,渲染编程还没那么快换掉 WebGL,WebGPU 的通用计算能力也可以在别的领域发光发热,更别说计算着色器在渲染中也是可以用的。
真是诱人啊!
Edge 和 Chrome 截至发文,在金丝雀版本均可以通过 flag 打开试用。
Edge 和 Chrome 均使用了 Chromium 核心,Chromium 是通过 Dawn 这个模块实现的 WebGPU API,根据有关资料,Dawn 中的 DawnNative 部分负责与三大图形 API 沟通,向上则给一个叫 DawnWire 的模块传递信息,DawnWire 模块则负责与 JavaScript API 沟通,也就是你写的 WebGPU 代码。WGSL 也是这个部分实现的。Dawn 是 C++ 实现的,你可以在参考资料中找到连接。
FireFox 则使用了 gfx-rs 项目实现 WebGPU,显然是 Rust 语言实现的 WebGPU,也有与 Dawn 类似的模块设计。
Safari 则更新自家的 WebKit 实现 WebGPU。
展望宏图之类的话不说,但是随着红绿蓝三家的 GPU 技术越发精湛,加上各个移动端的 GPU 逐渐起色,三大现代图形API肯定还在发展,WebGPU 一定能在 Web 端释放现代图形处理器(GPU)的强大能力,无论是图形游戏,亦或是通用并行计算带来的机器学习、AI能力。